
🎯 MỤC TIÊU
Về kiến thức:
- Hiểu được Machine Learning là gì trong bối cảnh nghiên cứu y khoa.
- Phân biệt được Machine Learning với thống kê truyền thống.
- Phân biệt được supervised learning và unsupervised learning.
- Mô tả được các thuật toán cơ bản: Logistic Regression, Decision Tree, Random Forest, XGBoost.
- Hiểu được quy trình xây dựng mô hình dự đoán y khoa.
- Giải thích được các chỉ số đánh giá mô hình: AUROC, sensitivity, specificity, PPV, NPV, calibration.
- Nhận diện được nguy cơ overfitting, data leakage, bias và thiếu external validation.
Về kỹ năng:
- Chuẩn bị được dữ liệu cơ bản cho machine learning.
- Chia dữ liệu thành train, validation và test set.
- Huấn luyện được mô hình dự đoán đơn giản bằng Python/Google Colab với AI hỗ trợ.
- So sánh được hiệu năng của Logistic Regression, Random Forest và XGBoost.
- Tạo được confusion matrix, ROC curve, calibration plot và bảng feature importance.
- Diễn giải được mô hình dự đoán bằng ngôn ngữ phù hợp với nhân viên y tế.
- Viết được đoạn báo cáo ngắn về mô hình theo tinh thần TRIPOD+AI.
Về thái độ:
- Không xem ML là “phép màu” thay thế tư duy lâm sàng.
- Không triển khai mô hình vào bệnh viện chỉ vì AUROC nhìn đẹp.
- Có ý thức kiểm tra tính công bằng, an toàn, khả năng áp dụng và bảo mật dữ liệu.
- Biết rằng mô hình dự đoán sai vẫn có thể trông rất tự tin — giống một bác sĩ nội trú mới đọc xong 3 bài review và bước vào giao ban với ánh mắt rực lửa.
Trong Bài 11, câu hỏi thường là:
“Yếu tố A có liên quan đến outcome B không?”
Trong Bài 12, câu hỏi thường là:
“Dựa trên nhiều thông tin đầu vào, ta có thể dự đoán outcome B chính xác đến đâu?”
Ví dụ:
| Cách hỏi thống kê truyền thống | Cách hỏi Machine Learning |
|---|---|
| BNP có liên quan đến tái nhập viện không? | Dựa trên tuổi, EF, BNP, bệnh đồng mắc và thời gian nằm viện, dự đoán ai sẽ tái nhập viện trong 30 ngày? |
| Điều trị A có giảm HbA1c không? | Dự đoán bệnh nhân nào sẽ không đạt HbA1c mục tiêu sau 3 tháng |
| Tuổi có liên quan tử vong ICU không? | Dự đoán nguy cơ tử vong ICU dựa trên nhiều biến lâm sàng |
PHẦN 1: MACHINE LEARNING LÀ GÌ?
1.1. Định nghĩa đơn giản
Machine Learning — Học máy là phương pháp cho phép máy tính học từ dữ liệu để phát hiện quy luật và đưa ra dự đoán hoặc phân loại trên dữ liệu mới.
Trong y khoa, ML thường được dùng để:
- Dự đoán nguy cơ bệnh.
- Dự đoán tử vong.
- Dự đoán tái nhập viện.
- Phân loại hình ảnh y khoa.
- Phát hiện bệnh nhân nguy cơ cao.
- Tìm pattern trong dữ liệu lớn.
- Hỗ trợ quyết định lâm sàng.
Ví dụ:
Dùng dữ liệu của 500 bệnh nhân suy tim đã xuất viện để huấn luyện mô hình dự đoán bệnh nhân nào có nguy cơ tái nhập viện trong 30 ngày.
1.2. Cách hiểu bằng ví dụ lâm sàng
Một bác sĩ tim mạch giàu kinh nghiệm nhìn bệnh nhân suy tim và “cảm giác” bệnh nhân này dễ tái nhập viện vì:
- Tuổi cao.
- EF thấp.
- BNP cao.
- Nhiều bệnh đồng mắc.
- Nằm viện lâu.
- Tiền sử nhập viện nhiều lần.
Machine Learning cũng học từ các yếu tố này, nhưng thay vì dựa vào kinh nghiệm cá nhân, nó học từ hàng trăm, hàng nghìn hoặc hàng triệu bệnh nhân.
Ẩn dụ:
Bác sĩ học từ ca bệnh. ML học từ dataset.
Bác sĩ có trực giác. ML có mô hình.
Cả hai đều có thể sai nếu dữ liệu đầu vào hoặc kinh nghiệm nền bị lệch. Không ai được đội vương miện quá sớm.
PHẦN 2: MACHINE LEARNING VS THỐNG KÊ TRUYỀN THỐNG
Khung chương trình gốc nhấn mạnh điểm khác biệt: thống kê truyền thống thường tập trung vào kiểm định giả thuyết, còn ML tập trung vào dự đoán outcome và phát hiện pattern.
2.1. So sánh tổng quan
| Tiêu chí | Thống kê truyền thống | Machine Learning |
|---|---|---|
| Mục tiêu chính | Giải thích, kiểm định giả thuyết | Dự đoán, phân loại, phát hiện pattern |
| Câu hỏi thường gặp | Yếu tố A có liên quan outcome B không? | Mô hình dự đoán outcome B tốt đến đâu? |
| Ưu tiên | Diễn giải, p-value, CI | Hiệu năng dự đoán, AUROC, calibration |
| Dữ liệu | Có thể nhỏ hơn | Thường cần dữ liệu lớn hơn |
| Mô hình | Thường đơn giản hơn | Có thể phức tạp hơn |
| Diễn giải | Dễ hơn | Có thể khó hơn, nhất là mô hình “hộp đen” |
| Ví dụ | Logistic regression để tìm yếu tố liên quan | Random Forest/XGBoost để dự đoán tái nhập viện |
2.2. Ví dụ cùng một dataset suy tim
Dataset gồm 500 bệnh nhân suy tim:
- Age.
- Ejection fraction.
- BNP.
- Diabetes.
- CKD.
- Length of stay.
- 30-day readmission.
Cách tiếp cận thống kê
BNP có liên quan đến tái nhập viện 30 ngày không sau khi hiệu chỉnh tuổi, EF và bệnh đồng mắc?
Kết quả mong muốn:
- Odds ratio.
- 95% confidence interval.
- p-value.
- Diễn giải yếu tố liên quan.
Cách tiếp cận ML
Dùng tất cả biến có sẵn để xây dựng mô hình dự đoán bệnh nhân nào sẽ tái nhập viện trong 30 ngày.
Kết quả mong muốn:
- AUROC.
- Sensitivity/specificity.
- Calibration.
- Confusion matrix.
- Feature importance.
- Khả năng ứng dụng lâm sàng.
2.3. Khi nào nên dùng ML trong y khoa?
Nên cân nhắc ML khi:
- Mục tiêu chính là dự đoán.
- Có nhiều biến đầu vào.
- Mối quan hệ giữa biến đầu vào và outcome có thể phức tạp.
- Có đủ dữ liệu chất lượng tốt.
- Có kế hoạch đánh giá mô hình trên dữ liệu chưa từng dùng để huấn luyện.
- Kết quả mô hình có thể hỗ trợ quyết định lâm sàng hoặc quản lý.
Không nên dùng ML chỉ vì:
- Nghe hiện đại.
- Muốn đề tài “AI” cho sang.
- Dataset có 50 bệnh nhân và 80 biến.
- Chưa làm sạch dữ liệu.
- Không có outcome rõ.
- Không biết mô hình sẽ dùng để làm gì.
Câu hỏi kiểm tra nhanh:
Nếu mô hình dự đoán ra kết quả, bác sĩ/điều dưỡng/bệnh viện sẽ hành động khác đi như thế nào?
Nếu không trả lời được, mô hình có thể chỉ là một món đồ chơi thống kê có đèn LED.
PHẦN 3: CÁC LOẠI MACHINE LEARNING CƠ BẢN
3.1. Supervised Learning — Học có giám sát
Đây là loại ML phổ biến nhất trong nghiên cứu y khoa dự đoán.
Máy học từ dữ liệu đã có:
Input features → Known outcome
Sau đó dùng mô hình để dự đoán outcome cho bệnh nhân mới.
Ví dụ
| Features | Outcome |
|---|---|
| Age, EF, BNP, comorbidities | Readmission trong 30 ngày: Có/Không |
| Tuổi, HbA1c, BMI, thuốc | Đạt HbA1c < 7%: Có/Không |
| Dấu hiệu sinh tồn, xét nghiệm | Tử vong ICU: Có/Không |
Hai dạng chính
| Dạng | Outcome | Ví dụ |
|---|---|---|
| Classification | Nhóm/nhị phân | Tái nhập viện: Có/Không |
| Regression | Số liên tục | Dự đoán HbA1c sau 3 tháng |
3.2. Unsupervised Learning — Học không giám sát
Máy học từ dữ liệu không có outcome đã gắn nhãn.
Mục tiêu là tìm pattern, nhóm bệnh nhân, cấu trúc ẩn.
Ví dụ
- Nhóm bệnh nhân đái tháo đường thành các phenotype khác nhau.
- Phân nhóm bệnh nhân ICU theo đặc điểm sinh lý.
- Tìm cluster bệnh nhân có kiểu sử dụng dịch vụ y tế tương tự.
- Giảm chiều dữ liệu xét nghiệm/hình ảnh.
Các phương pháp thường gặp
| Phương pháp | Mục tiêu |
|---|---|
| K-means clustering | Chia bệnh nhân thành nhóm |
| Hierarchical clustering | Tạo cây phân nhóm |
| PCA | Giảm số chiều dữ liệu |
| t-SNE/UMAP | Trực quan hóa dữ liệu phức tạp |
Trong Bài 12, trọng tâm là supervised learning vì dễ áp dụng vào prediction model lâm sàng.
PHẦN 4: CÁC THUẬT TOÁN CƠ BẢN TRONG BÀI 12
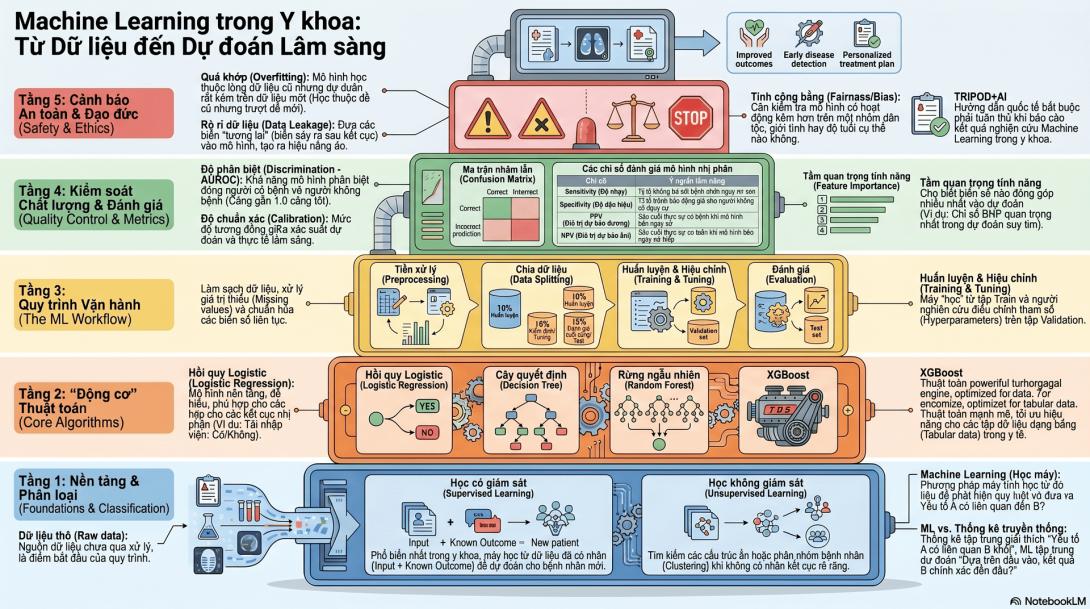
Khung chương trình gốc nêu các mô hình classification cơ bản gồm Logistic Regression, Decision Trees, Random Forest và thực hành thêm XGBoost.
4.1. Logistic Regression — Mô hình nền tảng
Dù tên là “regression”, logistic regression thường dùng cho outcome nhị phân.
Ví dụ outcome:
- Tái nhập viện: có/không.
- Tử vong: có/không.
- Đạt mục tiêu HbA1c: có/không.
- Có biến chứng: có/không.
Ưu điểm
- Dễ hiểu.
- Dễ báo cáo.
- Cho odds ratio.
- Là baseline model tốt.
- Phù hợp khi cần giải thích.
Hạn chế
- Giả định mối quan hệ tương đối tuyến tính giữa predictors và log-odds.
- Khó bắt mối quan hệ phức tạp nếu không thêm tương tác/biến đổi.
- Có thể kém hơn mô hình cây trong một số bài toán dự đoán.
Ví dụ diễn giải
Sau khi hiệu chỉnh các yếu tố khác, BNP cao hơn liên quan đến odds tái nhập viện 30 ngày cao hơn.
4.2. Decision Tree — Cây quyết định
Decision Tree chia dữ liệu thành các nhánh theo điều kiện.
Ví dụ:
BNP > 800?
├── Có → EF < 35?
│ ├── Có → Nguy cơ cao
│ └── Không → Nguy cơ trung bình
└── Không → Nguy cơ thấp
Ưu điểm
- Dễ trực quan hóa.
- Gần với cách suy nghĩ lâm sàng.
- Có thể xử lý quan hệ phi tuyến.
- Không cần chuẩn hóa biến liên tục.
Hạn chế
- Dễ overfit.
- Một thay đổi nhỏ trong dữ liệu có thể tạo cây khác.
- Hiệu năng thường không ổn định bằng Random Forest/XGBoost.
4.3. Random Forest — Rừng cây quyết định
Random Forest xây nhiều cây quyết định rồi tổng hợp kết quả.
Cách hiểu đơn giản
Một Decision Tree là một bác sĩ đưa ý kiến. Random Forest là hội chẩn nhiều bác sĩ, mỗi người nhìn một phần dữ liệu hơi khác nhau, rồi bỏ phiếu.
Ưu điểm
- Hiệu năng thường tốt.
- Ít overfit hơn một cây đơn lẻ.
- Xử lý quan hệ phi tuyến tốt.
- Cho feature importance.
Hạn chế
- Khó giải thích hơn logistic regression.
- Có nhiều hyperparameters.
- Cần cẩn thận với calibration.
- Feature importance có thể gây hiểu nhầm nếu biến tương quan mạnh.
4.4. XGBoost — Gradient Boosting mạnh mẽ
XGBoost là mô hình boosting, xây nhiều cây theo cách mỗi cây sau cố sửa lỗi của cây trước.
Ưu điểm
- Thường có hiệu năng dự đoán rất tốt.
- Xử lý dữ liệu dạng bảng mạnh.
- Có thể dùng cho nhiều bài toán classification/regression.
Hạn chế
- Dễ overfit nếu chỉnh sai.
- Cần tuning.
- Khó giải thích hơn.
- Không nên dùng như “búa thần” cho mọi dataset.
Lời nhắc:
XGBoost không biến dataset dở thành nghiên cứu tốt. Nó chỉ giúp dataset dở chạy nhanh hơn tới kết quả dở — rất năng suất, nhưng hơi buồn.
PHẦN 5: QUY TRÌNH MACHINE LEARNING TRONG Y KHOA
Khung chương trình gốc nêu workflow gồm: data preprocessing, feature selection, train/validation/test split, model training, hyperparameter tuning và evaluation bằng AUROC/calibration.
5.1. Sơ đồ tổng quan
Câu hỏi dự đoán
↓
Xác định outcome và predictors
↓
Làm sạch dữ liệu
↓
Tiền xử lý dữ liệu
↓
Chia train / validation / test
↓
Huấn luyện mô hình
↓
Tuning
↓
Đánh giá mô hình
↓
Diễn giải và kiểm tra bias
↓
Báo cáo theo TRIPOD+AI
↓
External validation trước khi triển khai
5.2. Bước 1 — Xác định câu hỏi dự đoán
Một câu hỏi ML tốt cần rõ:
- Ai là population?
- Outcome cần dự đoán là gì?
- Dự đoán tại thời điểm nào?
- Dữ liệu đầu vào có sẵn trước thời điểm dự đoán không?
- Mô hình dùng để làm gì?
Câu hỏi yếu
Dự đoán suy tim.
Quá mơ hồ.
Câu hỏi tốt hơn
Ở bệnh nhân suy tim xuất viện từ khoa Tim mạch, liệu dữ liệu tại thời điểm xuất viện có thể dự đoán nguy cơ tái nhập viện trong vòng 30 ngày không?
Câu hỏi rất tốt
Xây dựng và đánh giá mô hình dự đoán tái nhập viện 30 ngày ở bệnh nhân suy tim xuất viện, sử dụng các biến lâm sàng có sẵn tại thời điểm xuất viện gồm tuổi, EF, BNP, bệnh đồng mắc và thời gian nằm viện.
5.3. Bước 2 — Xác định outcome
Outcome phải rõ, đo được và có ý nghĩa lâm sàng.
Ví dụ:
Readmission_30d = 1 nếu bệnh nhân tái nhập viện trong vòng 30 ngày sau xuất viện
Readmission_30d = 0 nếu không tái nhập viện trong vòng 30 ngày
Lưu ý
Phải định nghĩa:
- Tái nhập viện cùng bệnh viện hay bất kỳ bệnh viện nào?
- Tái nhập viện vì mọi nguyên nhân hay vì suy tim?
- Tính từ ngày xuất viện hay ngày nhập viện ban đầu?
- Bệnh nhân tử vong trước 30 ngày xử lý thế nào?
Outcome không rõ thì mô hình học rất chăm chỉ… điều sai.
5.4. Bước 3 — Chọn features
Features là biến đầu vào cho mô hình.
Trong project mẫu:
- Age.
- EF.
- BNP.
- Comorbidities.
- Length of stay.
Có thể mở rộng thêm:
- Sex.
- NYHA class.
- eGFR.
- Sodium.
- Hemoglobin.
- Prior hospitalization.
- Medication at discharge.
- Blood pressure.
- Heart rate.
Nguyên tắc chọn features
Chỉ dùng biến có sẵn trước hoặc tại thời điểm dự đoán.
Ví dụ, nếu dự đoán tái nhập viện tại thời điểm xuất viện thì không được dùng:
- Số lần tái khám sau xuất viện.
- Thuốc thay đổi sau 2 tuần.
- Xét nghiệm sau tái nhập viện.
- Dữ liệu xảy ra sau outcome.
Đưa biến tương lai vào mô hình gọi là data leakage. Nó làm mô hình đẹp như tranh, nhưng đem ra thực tế thì rụng như lá mùa mưa.
5.5. Bước 4 — Tiền xử lý dữ liệu
Gồm:
- Kiểm tra missing values.
- Imputation.
- Encode biến phân loại.
- Chuẩn hóa biến liên tục.
- Xử lý outliers nếu có lý do.
- Kiểm tra mất cân bằng outcome.
- Ghi lại toàn bộ quyết định.
Missing values
Ví dụ:
| Biến | Cách xử lý đơn giản |
|---|---|
| Age | Median imputation |
| BNP | Median imputation hoặc tạo thêm missing indicator |
| Sex | Mode imputation |
| Comorbidities | Kiểm tra hồ sơ; không nên đoán bừa |
Encoding
Biến phân loại phải được chuyển thành số.
Ví dụ:
Sex: Male/Female → 0/1
NYHA class: I/II/III/IV → ordinal hoặc one-hot encoding tùy mục tiêu
Comorbidities: Diabetes, CKD, COPD → mỗi bệnh là một biến 0/1
Standardization
Một số mô hình như logistic regression cần chuẩn hóa biến liên tục để huấn luyện ổn định hơn.
Standardized value = (giá trị - trung bình) / độ lệch chuẩn
Tree-based models như Random Forest/XGBoost thường không bắt buộc chuẩn hóa, nhưng pipeline thống nhất vẫn hữu ích.
5.6. Bước 5 — Chia train/validation/test
Khung thực hành gốc yêu cầu chia dữ liệu thành train 70%, validation 15%, test 15%.
| Tập dữ liệu | Mục đích |
|---|---|
| Train set | Huấn luyện mô hình |
| Validation set | Chọn mô hình, tuning hyperparameters |
| Test set | Đánh giá cuối cùng, chỉ dùng một lần |
Nguyên tắc vàng
Không được dùng test set để tuning. Nếu cứ nhìn test set rồi chỉnh tiếp mô hình, test set không còn là “bài thi cuối kỳ” nữa mà thành “đề cương ôn tập có đáp án”.
5.7. Bước 6 — Huấn luyện mô hình
Trong bài này, học viên huấn luyện 3 mô hình:
- Logistic Regression.
- Random Forest.
- XGBoost.
Logistic Regression đóng vai trò baseline. Nếu mô hình phức tạp không tốt hơn baseline hoặc khó giải thích hơn nhiều, chưa chắc đáng dùng.
5.8. Bước 7 — Tuning hyperparameters
Hyperparameters là các thiết lập trước khi mô hình học.
Ví dụ Random Forest:
- Number of trees.
- Maximum depth.
- Minimum samples per leaf.
Ví dụ XGBoost:
- Learning rate.
- Max depth.
- Number of estimators.
- Subsample.
Lưu ý cho người mới
Không cần tuning quá sâu trong Bài 12. Mục tiêu là hiểu workflow, không phải biến buổi học thành cuộc thi Kaggle mini.
5.9. Bước 8 — Đánh giá mô hình
Cần đánh giá ít nhất:
- Discrimination — phân biệt người có/không có outcome.
- Calibration — xác suất dự đoán có đúng thực tế không.
- Clinical usefulness — mô hình có giúp ra quyết định không?
- Fairness — mô hình có hoạt động kém trên nhóm nào không?
- Generalizability — mô hình có dùng được ở bệnh viện khác không?
PHẦN 6: CÁC CHỈ SỐ ĐÁNH GIÁ MÔ HÌNH
6.1. Confusion Matrix
Với outcome nhị phân:
| Thực tế có outcome | Thực tế không outcome | |
|---|---|---|
| Dự đoán có outcome | True Positive | False Positive |
| Dự đoán không outcome | False Negative | True Negative |
Ví dụ trong tái nhập viện:
- True Positive: Mô hình dự đoán tái nhập viện và bệnh nhân thật sự tái nhập viện.
- False Positive: Mô hình dự đoán tái nhập viện nhưng bệnh nhân không tái nhập viện.
- False Negative: Mô hình dự đoán không tái nhập viện nhưng bệnh nhân tái nhập viện.
- True Negative: Mô hình dự đoán không tái nhập viện và bệnh nhân không tái nhập viện.
6.2. Sensitivity và Specificity
Sensitivity — Độ nhạy
Trong số bệnh nhân thật sự tái nhập viện, mô hình phát hiện được bao nhiêu phần trăm?
Cao sensitivity nếu muốn không bỏ sót bệnh nhân nguy cơ cao.
Specificity — Độ đặc hiệu
Trong số bệnh nhân không tái nhập viện, mô hình nhận diện đúng bao nhiêu phần trăm?
Cao specificity nếu muốn tránh báo động giả quá nhiều.
6.3. PPV và NPV
Positive Predictive Value — PPV
Trong số bệnh nhân được dự đoán nguy cơ cao, bao nhiêu người thật sự tái nhập viện?
Negative Predictive Value — NPV
Trong số bệnh nhân được dự đoán nguy cơ thấp, bao nhiêu người thật sự không tái nhập viện?
PPV và NPV phụ thuộc vào tỷ lệ outcome trong quần thể. Mô hình dùng tốt ở bệnh viện trung ương chưa chắc dùng tốt ở bệnh viện huyện nếu case-mix khác.
6.4. AUROC
AUROC đo khả năng mô hình phân biệt người có outcome và không có outcome.
| AUROC | Diễn giải gần đúng |
|---|---|
| 0,5 | Không tốt hơn đoán mò |
| 0,6–0,7 | Yếu |
| 0,7–0,8 | Chấp nhận được |
| 0,8–0,9 | Tốt |
| >0,9 | Rất tốt, nhưng cần kiểm tra overfitting/data leakage |
Lưu ý
AUROC cao không đảm bảo mô hình hữu ích lâm sàng. Một mô hình AUROC 0,85 nhưng calibration tệ có thể đưa ra xác suất nguy cơ sai lệch.
6.5. Calibration
Calibration trả lời:
Nếu mô hình dự đoán 100 bệnh nhân có nguy cơ 20%, có khoảng 20 người thật sự xảy ra outcome không?
Một mô hình có discrimination tốt nhưng calibration kém giống như một người xếp hạng bệnh nhân khá đúng nhưng luôn phóng đại nguy cơ. Lâm sàng nghe xong là hơi run.
Ví dụ
- Mô hình nói nguy cơ tái nhập viện 70%.
- Thực tế nhóm đó chỉ có 30% tái nhập viện.
Mô hình này có thể làm bác sĩ can thiệp quá mức.
6.6. Feature importance
Feature importance cho biết biến nào đóng góp nhiều vào dự đoán.
Ví dụ:
| Feature | Importance |
|---|---|
| BNP | 0,28 |
| EF | 0,22 |
| Length of stay | 0,18 |
| Age | 0,12 |
| CKD | 0,10 |
Cẩn thận
Feature importance không đồng nghĩa với quan hệ nhân quả. Nếu BNP quan trọng nhất, không có nghĩa giảm BNP bằng mọi giá sẽ chắc chắn giảm tái nhập viện. Mô hình đang dự đoán, không đang chứng minh cơ chế.
PHẦN 7: OVERFITTING, DATA LEAKAGE VÀ BIAS
Khung chương trình gốc yêu cầu thảo luận phê phán về overfitting, nhu cầu external validation, rào cản triển khai lâm sàng và vấn đề đạo đức.
7.1. Overfitting là gì?
Overfitting xảy ra khi mô hình học quá kỹ dữ liệu huấn luyện, bao gồm cả nhiễu, nên biểu hiện rất tốt trên training set nhưng kém trên dữ liệu mới.
Dấu hiệu
| Training performance | Test performance | Diễn giải |
|---|---|---|
| AUROC 0,98 | AUROC 0,62 | Overfitting rất đáng nghi |
| Accuracy 95% | Accuracy 70% | Mô hình học thuộc bài |
| Random Forest/XGBoost quá đẹp | Test set xấu | Cần giảm độ phức tạp |
Ẩn dụ:
Overfitting giống học thuộc đáp án đề năm ngoái. Vào phòng thi gặp đề mới thì mô hình cũng toát mồ hôi, nếu mô hình có tuyến mồ hôi.
7.2. Data leakage
Data leakage xảy ra khi mô hình vô tình được cung cấp thông tin không nên có.
Ví dụ data leakage trong y khoa
| Leakage | Vì sao sai |
|---|---|
| Dùng biến “số lần tái khám sau xuất viện” để dự đoán tái nhập viện 30 ngày | Biến này xảy ra sau thời điểm dự đoán |
| Imputation/standardization trước khi chia train-test | Test set đã “rò” thông tin vào train |
| Dùng kết quả xét nghiệm sau biến cố | Không có sẵn tại thời điểm dự đoán |
| Dùng mã chẩn đoán discharge để dự đoán biến cố xảy ra trong viện | Biến được tạo sau outcome |
Nguyên tắc
Tất cả bước học từ dữ liệu — imputation, scaling, feature selection — phải được fit trên training set rồi áp dụng sang validation/test.
7.3. Bias trong mô hình ML
Mô hình có thể hoạt động kém hơn trên một số nhóm:
- Nam/nữ.
- Người cao tuổi.
- Bệnh viện tuyến tỉnh vs tuyến trung ương.
- Thành thị vs nông thôn.
- Nhóm dân tộc thiểu số.
- Người có ít dữ liệu xét nghiệm.
- Bệnh nhân nghèo ít tái khám đầy đủ.
Câu hỏi kiểm tra fairness
- AUROC có khác giữa nam và nữ không?
- Calibration có khác giữa nhóm tuổi trẻ và cao tuổi không?
- Mô hình có bỏ sót bệnh nhân nông thôn nhiều hơn không?
- Dữ liệu huấn luyện có đại diện cho bệnh viện nơi triển khai không?
PHẦN 8: REPORTING ML MODELS — TRIPOD+AI
Khung chương trình gốc yêu cầu học viên biết reporting ML models theo TRIPOD+AI và các yêu cầu minh bạch.
8.1. Vì sao cần guideline báo cáo?
Một mô hình ML y khoa không chỉ cần “chạy được”. Nó cần được báo cáo đủ rõ để người khác đánh giá:
- Dữ liệu từ đâu?
- Ai được đưa vào?
- Outcome định nghĩa thế nào?
- Missing data xử lý ra sao?
- Dữ liệu được chia train/test thế nào?
- Model nào được thử?
- Hyperparameters ra sao?
- Đánh giá bằng chỉ số nào?
- Có external validation không?
- Có kiểm tra bias không?
- Có mã nguồn hoặc pipeline không?
8.2. Các thông tin tối thiểu cần báo cáo
| Thành phần | Cần báo cáo |
|---|---|
| Population | Nguồn dữ liệu, tiêu chuẩn chọn/loại |
| Prediction timepoint | Dự đoán tại thời điểm nào |
| Outcome | Định nghĩa, thời gian theo dõi |
| Predictors | Danh sách biến, thời điểm thu thập |
| Missing data | Tỷ lệ thiếu, cách xử lý |
| Data split | Train/validation/test hoặc cross-validation |
| Algorithms | Loại mô hình, hyperparameters |
| Evaluation | AUROC, calibration, confusion matrix |
| Interpretability | Feature importance/SHAP nếu có |
| Validation | Internal/external validation |
| Ethics | Bảo mật, bias, khả năng gây hại |
| AI assistance | Công cụ AI đã dùng, dùng để làm gì |
PHẦN 9: CÔNG CỤ SỬ DỤNG TRONG BÀI
Khung chương trình gốc liệt kê 3 công cụ chính: ChatGPT với Code Interpreter, Google Colab và Julius AI.
9.1. ChatGPT với Code Interpreter / Advanced Data Analysis
Dùng để:
- Viết code Python.
- Giải thích code.
- Tạo pipeline ML.
- Kiểm tra lỗi.
- Tạo biểu đồ ROC, confusion matrix, calibration.
- Hỗ trợ viết phần Results.
Lưu ý
Không upload dữ liệu định danh bệnh nhân lên công cụ AI công cộng. Nếu cần thực hành, dùng dataset giả lập hoặc đã ẩn danh.
9.2. Google Colab
Dùng để:
- Chạy Python miễn phí.
- Cài thư viện scikit-learn, xgboost.
- Chia sẻ notebook với nhóm.
- Tái lập phân tích.
Ưu điểm lớn: học viên không cần cài Python trên máy cá nhân.
9.3. Julius AI
Dùng cho:
- Phân tích dữ liệu bằng câu hỏi tự nhiên.
- Tạo mô hình đơn giản.
- Vẽ biểu đồ nhanh.
- Hỗ trợ học viên chưa quen code.
Lưu ý: vẫn cần kiểm tra bảo mật dữ liệu và hiểu logic mô hình.
PHẦN 10: PROJECT THỰC HÀNH TRÊN LỚP
Chủ đề project
Xây dựng mô hình dự đoán tái nhập viện 30 ngày ở bệnh nhân suy tim.
Đây là project thực hành chính được nêu trong khung chương trình gốc. Dataset mẫu gồm 500 bệnh nhân suy tim xuất viện, outcome là tái nhập viện trong 30 ngày, features gồm tuổi, EF, BNP, bệnh đồng mắc và thời gian nằm viện.
10.1. Cấu trúc dataset mẫu
| Biến | Ý nghĩa | Loại biến |
|---|---|---|
| Patient_ID | Mã bệnh nhân | ID |
| Age | Tuổi | Liên tục |
| Sex | Giới | Categorical |
| EF | Ejection fraction | Liên tục |
| BNP | B-type natriuretic peptide | Liên tục |
| Diabetes | Có đái tháo đường | Nhị phân |
| CKD | Có bệnh thận mạn | Nhị phân |
| COPD | Có COPD | Nhị phân |
| Prior_HF_Admission | Tiền sử nhập viện vì suy tim | Nhị phân |
| Length_of_Stay | Số ngày nằm viện | Liên tục |
| Discharge_Medication_Count | Số thuốc lúc xuất viện | Liên tục |
| Readmission_30d | Tái nhập viện trong 30 ngày | Outcome nhị phân |
10.2. Thực hành 1 — Chuẩn bị dữ liệu
Thời lượng: 25 phút
Nhiệm vụ
- Kiểm tra missing values.
- Xử lý missing bằng median/mode imputation.
- Encode biến categorical.
- Chia train/validation/test 70/15/15.
- Standardize continuous variables.
- Đảm bảo không data leakage.
Prompt mẫu
Tôi có dataset gồm 500 bệnh nhân suy tim xuất viện.
Outcome:
- Readmission_30d: 1 = tái nhập viện trong 30 ngày, 0 = không
Features:
- Age
- Sex
- EF
- BNP
- Diabetes
- CKD
- COPD
- Prior_HF_Admission
- Length_of_Stay
- Discharge_Medication_Count
Hãy viết code Python trong Google Colab để chuẩn bị dữ liệu cho machine learning:
Yêu cầu:
1. Load file CSV
2. Kiểm tra missing values
3. Tách X và y
4. Chia train/validation/test theo tỷ lệ 70/15/15, dùng stratify theo outcome
5. Với biến liên tục: impute bằng median và standardize
6. Với biến categorical: impute bằng mode và one-hot encode nếu cần
7. Tạo sklearn Pipeline để tránh data leakage
8. In kích thước từng tập dữ liệu
9. Có comment bằng tiếng Việt
10.3. Thực hành 2 — Huấn luyện 3 mô hình
Thời lượng: 25 phút
Mô hình cần huấn luyện
- Logistic Regression.
- Random Forest.
- XGBoost.
Prompt mẫu
Tiếp tục từ dữ liệu đã chia train/validation/test.
Hãy viết code Python để huấn luyện 3 mô hình dự đoán Readmission_30d:
1. Logistic Regression
2. Random Forest
3. XGBoost
Yêu cầu:
- Sử dụng pipeline preprocessing đã tạo
- Huấn luyện trên train set
- Đánh giá sơ bộ trên validation set
- In AUROC, accuracy, sensitivity, specificity, PPV, NPV
- Lưu kết quả vào một bảng so sánh
- Có comment bằng tiếng Việt
10.4. Thực hành 3 — Đánh giá mô hình
Thời lượng: 25 phút
Khung chương trình gốc yêu cầu đánh giá bằng AUROC, calibration plot, confusion matrix và feature importance.
Nhiệm vụ
- Chọn model tốt nhất dựa trên validation set.
- Đánh giá cuối cùng trên test set.
- Vẽ ROC curve.
- Tạo confusion matrix.
- Vẽ calibration plot.
- Xuất feature importance.
Prompt mẫu
Tôi đã huấn luyện 3 mô hình:
- Logistic Regression
- Random Forest
- XGBoost
Hãy viết code Python để đánh giá mô hình tốt nhất trên test set.
Yêu cầu:
1. Tính AUROC
2. Vẽ ROC curve
3. Tạo confusion matrix tại threshold 0.5
4. Tính sensitivity, specificity, PPV, NPV
5. Vẽ calibration plot
6. Tạo bảng predicted risk theo nhóm nguy cơ:
- Low risk: <10%
- Moderate risk: 10–20%
- High risk: >20%
7. Xuất feature importance nếu mô hình hỗ trợ
8. Viết đoạn diễn giải kết quả bằng tiếng Việt
10.5. Thực hành 4 — Diễn giải khả năng ứng dụng lâm sàng
Thời lượng: 15 phút
Câu hỏi thảo luận
- Mô hình nào có AUROC tốt nhất?
- Mô hình nào dễ giải thích nhất?
- Top predictors là gì?
- Mô hình có calibration tốt không?
- Nếu dùng mô hình này tại bệnh viện, ai sẽ nhận cảnh báo?
- Cảnh báo nguy cơ cao sẽ dẫn đến hành động gì?
- False positive và false negative có hậu quả gì?
- Mô hình có cần external validation không?
Mẫu diễn giải
Mô hình Random Forest đạt AUROC cao nhất trên validation set, tuy nhiên Logistic Regression có ưu điểm dễ diễn giải hơn và hiệu năng chỉ thấp hơn nhẹ. Trên test set, mô hình tốt nhất đạt AUROC = ..., sensitivity = ..., specificity = .... Các yếu tố dự đoán quan trọng nhất gồm BNP, EF, tiền sử nhập viện suy tim và thời gian nằm viện. Tuy nhiên, mô hình mới chỉ được đánh giá nội bộ trên một dataset giả lập/một trung tâm, cần external validation trước khi cân nhắc ứng dụng lâm sàng.
PHẦN 11: DIỄN GIẢI MÔ HÌNH CHO NHÂN VIÊN Y TẾ
11.1. Không nên nói
“Mô hình AI này dự đoán chính xác bệnh nhân sẽ tái nhập viện.”
Quá mạnh. Không mô hình nào dự đoán chắc chắn tương lai từng bệnh nhân.
11.2. Nên nói
“Mô hình ước tính xác suất tái nhập viện trong 30 ngày dựa trên các đặc điểm có sẵn tại thời điểm xuất viện.”
11.3. Ví dụ diễn giải cho bệnh viện
Bệnh nhân có nguy cơ dự đoán >20% có thể được xem xét tư vấn xuất viện tăng cường, hẹn tái khám sớm hơn, gọi điện theo dõi sau xuất viện hoặc chuyển vào chương trình quản lý suy tim. Tuy nhiên, mô hình chỉ hỗ trợ phân tầng nguy cơ, không thay thế đánh giá lâm sàng của bác sĩ.
PHẦN 12: CASE STUDY THẢO LUẬN
Case 1: AUROC rất cao — vui hay lo?
Một nhóm xây mô hình dự đoán tái nhập viện 30 ngày. AUROC trên test set = 0,98.
Câu hỏi
- Đây có phải mô hình cực tốt không?
- Cần kiểm tra điều gì?
- Nguy cơ nào đáng nghi?
Gợi ý trả lời
AUROC 0,98 trong dữ liệu y khoa dạng bảng là rất cao, cần kiểm tra data leakage, biến xảy ra sau outcome, trùng bệnh nhân giữa train/test, test set quá nhỏ hoặc outcome bị mã hóa gián tiếp qua một biến khác.
Case 2: Mô hình tốt nhưng không dùng được
Mô hình dự đoán tử vong ICU có AUROC 0,87. Tuy nhiên, biến quan trọng nhất là xét nghiệm chỉ có sau 48 giờ nằm ICU, trong khi bệnh viện muốn dự đoán ngay lúc nhập ICU.
Câu hỏi
- Vấn đề là gì?
- Mô hình có phù hợp mục tiêu lâm sàng không?
- Nên sửa thế nào?
Gợi ý trả lời
Mô hình dùng biến không có sẵn tại thời điểm cần dự đoán. Cần xác định lại prediction timepoint và chỉ dùng biến có sẵn tại thời điểm đó.
Case 3: Mô hình kém ở bệnh viện tuyến huyện
Mô hình được huấn luyện tại bệnh viện trung ương, AUROC nội bộ 0,82. Khi áp dụng tại bệnh viện huyện, AUROC còn 0,61 và calibration rất kém.
Câu hỏi
- Vì sao mô hình giảm hiệu năng?
- Đây là vấn đề gì?
- Cần làm gì trước khi triển khai rộng?
Gợi ý trả lời
Có thể do khác biệt case-mix, quy trình điều trị, cách ghi dữ liệu, tỷ lệ outcome và nguồn lực. Đây là vấn đề generalizability và external validation. Cần kiểm định ngoài, hiệu chỉnh calibration, hoặc huấn luyện lại với dữ liệu địa phương.
Case 4: Mô hình gây quá tải chăm sóc
Mô hình đánh dấu 45% bệnh nhân là nguy cơ cao. Điều dưỡng chỉ đủ nhân lực gọi điện theo dõi 10% bệnh nhân sau xuất viện.
Câu hỏi
- Threshold 0,5 có phù hợp không?
- Nên chọn threshold theo tiêu chí nào?
- Mô hình có cần gắn với nguồn lực thực tế không?
Gợi ý trả lời
Threshold cần chọn theo mục tiêu lâm sàng và nguồn lực. Có thể chọn top 10% nguy cơ cao nhất thay vì threshold cố định. Mô hình phải phục vụ quy trình chăm sóc thật, không phải tạo thêm việc rồi bỏ đó.
PHẦN 13: AI HỖ TRỢ MACHINE LEARNING NHƯ THẾ NÀO?
13.1. AI có thể hỗ trợ
- Viết code Python.
- Giải thích thuật toán.
- Tạo pipeline preprocessing.
- Gợi ý mô hình.
- Vẽ ROC curve, confusion matrix, calibration plot.
- Viết báo cáo kết quả.
- Phát hiện lỗi logic trong pipeline.
- Tạo checklist TRIPOD+AI.
- Giải thích output cho người không chuyên code.
13.2. AI không được quyết định thay
- Outcome nào có ý nghĩa lâm sàng.
- Biến nào hợp lệ tại thời điểm dự đoán.
- Có nên triển khai mô hình hay không.
- Mô hình có công bằng không.
- Có đủ an toàn cho bệnh nhân không.
- Có được dùng dữ liệu bệnh nhân lên cloud hay không.
- Có thể thay quyết định bác sĩ hay không.
13.3. Prompt kiểm tra pipeline ML
Hãy đóng vai trò chuyên gia machine learning trong y khoa.
Đánh giá pipeline sau:
[Dán mô tả pipeline hoặc code]
Hãy kiểm tra:
1. Có nguy cơ data leakage không?
2. Train/validation/test split có hợp lý không?
3. Imputation và standardization có được fit chỉ trên training set không?
4. Outcome có được định nghĩa rõ không?
5. Có biến nào xảy ra sau thời điểm dự đoán không?
6. Chỉ số đánh giá có phù hợp không?
7. Có cần calibration không?
8. Có cần external validation không?
9. Có vấn đề đạo đức hoặc bias nào cần lưu ý không?
10. Đề xuất sửa cụ thể.
PHẦN 14: LỖI THƯỜNG GẶP KHI LÀM ML Y KHOA
| Lỗi | Ví dụ | Hậu quả | Cách sửa |
|---|---|---|---|
| Outcome mơ hồ | “Bệnh nhân xấu đi” | Mô hình học sai mục tiêu | Định nghĩa outcome cụ thể |
| Data leakage | Dùng dữ liệu sau xuất viện để dự đoán tại lúc xuất viện | Hiệu năng ảo | Chỉ dùng biến có sẵn trước thời điểm dự đoán |
| Không chia test set | Huấn luyện và đánh giá trên cùng dữ liệu | Overfitting | Train/validation/test split |
| Test set bị dùng nhiều lần | Chỉnh model theo test set | Test set mất giá trị | Chỉ dùng test set cuối cùng |
| Chỉ báo accuracy | Outcome hiếm 5%, đoán “không” cũng 95% accuracy | Đánh giá sai | Dùng AUROC, sensitivity, specificity, PPV/NPV |
| Không kiểm tra calibration | AUROC cao nhưng xác suất sai | Quyết định lâm sàng sai | Vẽ calibration plot |
| Không external validation | Model chỉ tốt ở một nơi | Triển khai thất bại | Kiểm định ngoài |
| Không xem fairness | Model kém ở nhóm nông thôn | Bất công | Phân tích theo subgroup |
| Không bảo mật dữ liệu | Upload file bệnh nhân lên AI public | Vi phạm đạo đức/pháp lý | Ẩn danh, dùng môi trường an toàn |
| Diễn giải causal | Feature importance = nguyên nhân | Kết luận sai | Nhấn mạnh mô hình dự đoán, không chứng minh nhân quả |
PHẦN 15: CHECKLIST SAU BÀI HỌC
15.1. Checklist câu hỏi ML
- Population rõ.
- Outcome rõ.
- Prediction timepoint rõ.
- Features có sẵn tại thời điểm dự đoán.
- Mục đích sử dụng mô hình rõ.
- Có kế hoạch xử lý missing data.
- Có kế hoạch train/validation/test split.
- Có kế hoạch đánh giá discrimination và calibration.
- Có kế hoạch kiểm tra bias/fairness.
- Có kế hoạch external validation nếu muốn triển khai.
15.2. Checklist kỹ thuật
- Không có patient identifiers trong file dùng thực hành.
- Imputation fit trên training set.
- Scaling fit trên training set.
- Test set không dùng để tuning.
- Có confusion matrix.
- Có ROC curve/AUROC.
- Có calibration plot.
- Có feature importance hoặc giải thích mô hình.
- Có ghi lại tool, version, ngày phân tích.
- Có lưu code/notebook để tái lập.
15.3. Checklist diễn giải
- Không nói “AI chứng minh”.
- Không nói “dự đoán chính xác tuyệt đối”.
- Không suy luận nhân quả từ feature importance.
- Có nêu giới hạn dataset.
- Có nêu cần external validation.
- Có nêu khả năng ứng dụng lâm sàng.
- Có nêu rủi ro false positive/false negative.
- Có nêu trách nhiệm con người khi dùng mô hình.
PHẦN 16: THƯ VIỆN PROMPT CHO BÀI 12
Prompt 1: Xác định bài toán ML
Tôi muốn xây dựng mô hình machine learning trong nghiên cứu y khoa.
Thông tin:
- Bối cảnh lâm sàng:
- Population:
- Outcome muốn dự đoán:
- Thời điểm dự đoán:
- Các biến đầu vào có sẵn:
- Mục đích sử dụng mô hình:
- Cỡ mẫu:
- Tỷ lệ outcome:
Hãy đánh giá:
1. Đây có phải bài toán ML phù hợp không?
2. Là classification hay regression?
3. Outcome có đủ rõ không?
4. Có nguy cơ data leakage nào không?
5. Nên dùng mô hình baseline nào?
6. Chỉ số đánh giá nào phù hợp?
7. Những điểm cần làm rõ trước khi phân tích.
Prompt 2: Viết code ML đầy đủ
Hãy viết code Python trong Google Colab để xây dựng mô hình dự đoán y khoa.
Dataset: CSV
Outcome: Readmission_30d
Features:
Age, Sex, EF, BNP, Diabetes, CKD, COPD, Prior_HF_Admission, Length_of_Stay
Yêu cầu:
1. Load dữ liệu
2. Kiểm tra missing values
3. Tách X/y
4. Chia train/validation/test 70/15/15, stratify theo outcome
5. Tạo preprocessing pipeline:
- Continuous: median imputation + standardization
- Categorical: mode imputation + one-hot encoding
6. Train Logistic Regression, Random Forest, XGBoost
7. Đánh giá validation set bằng AUROC, sensitivity, specificity, PPV, NPV
8. Chọn model tốt nhất
9. Đánh giá model tốt nhất trên test set
10. Vẽ ROC curve, confusion matrix, calibration plot
11. Xuất feature importance
12. Comment code bằng tiếng Việt
13. Giải thích từng bước sau code
Prompt 3: Diễn giải kết quả ML
Dưới đây là kết quả mô hình ML:
[Dán bảng kết quả]
Hãy viết phần Results ngắn cho manuscript y khoa, gồm:
1. Số bệnh nhân và tỷ lệ outcome
2. Cách chia train/validation/test
3. Các mô hình đã thử
4. Hiệu năng trên validation set
5. Hiệu năng cuối cùng trên test set
6. AUROC, sensitivity, specificity, PPV, NPV
7. Calibration nếu có
8. Top predictors
9. Diễn giải thận trọng, không nói quá mức
Viết bằng tiếng Việt học thuật và kèm bản tiếng Anh.
Prompt 4: Kiểm tra đạo đức và triển khai
Tôi có mô hình dự đoán [outcome] trong bệnh viện.
Thông tin mô hình:
- Population:
- Dataset:
- Outcome:
- Features:
- AUROC:
- Calibration:
- Top predictors:
- Intended use:
- Ai sẽ dùng mô hình:
- Hành động sau khi model báo nguy cơ cao:
Hãy đánh giá:
1. Mô hình đã đủ điều kiện triển khai chưa?
2. Cần external validation gì?
3. Nguy cơ bias/fairness nào?
4. False positive gây hại gì?
5. False negative gây hại gì?
6. Cần giải thích với bệnh nhân/nhân viên y tế như thế nào?
7. Cần giám sát mô hình sau triển khai ra sao?
8. Có nên dùng như decision support hay tự động quyết định?
PHẦN 17: BÀI TẬP VỀ NHÀ
Bài tập chính: Mini Prediction Model
Mỗi học viên hoặc nhóm nhỏ thực hiện một mini-project ML với dataset mẫu hoặc dữ liệu đã ẩn danh.
Yêu cầu nộp
- Câu hỏi dự đoán
- Population.
- Outcome.
- Prediction timepoint.
- Intended use.
- Mô tả dataset
- Số bệnh nhân.
- Số predictors.
- Tỷ lệ outcome.
- Missing data.
- Preprocessing
- Missing imputation.
- Encoding.
- Standardization.
- Train/validation/test split.
- Models
- Logistic Regression.
- Một tree-based model: Random Forest hoặc XGBoost.
- Evaluation
- AUROC.
- Confusion matrix.
- Sensitivity/specificity.
- PPV/NPV.
- Calibration plot.
- Feature importance.
- Interpretation
- Model nào tốt nhất?
- Top predictors là gì?
- Có ứng dụng lâm sàng không?
- Cần external validation không?
- Reflection 200–300 từ
- AI đã giúp gì?
- AI gợi ý sai hoặc chưa đủ ở đâu?
- Bạn đã kiểm tra data leakage thế nào?
- Có rủi ro đạo đức/bias nào?
Mẫu bài nộp
Tên project:
Dự đoán tái nhập viện 30 ngày ở bệnh nhân suy tim xuất viện.
Câu hỏi dự đoán:
Ở bệnh nhân suy tim xuất viện, dữ liệu lâm sàng tại thời điểm xuất viện có thể dự đoán tái nhập viện trong 30 ngày không?
Dataset:
- n = 500
- Outcome: Readmission_30d
- Outcome rate: 18%
- Predictors: Age, EF, BNP, Diabetes, CKD, COPD, Prior_HF_Admission, Length_of_Stay
Preprocessing:
- Continuous variables: median imputation + standardization
- Categorical variables: mode imputation + one-hot encoding
- Split: train 70%, validation 15%, test 15%
Models:
- Logistic Regression
- Random Forest
- XGBoost
Main result:
Model tốt nhất trên validation set là ...
Trên test set, AUROC = ..., sensitivity = ..., specificity = ...
Top predictors gồm ...
Clinical interpretation:
Mô hình có thể hỗ trợ xác định bệnh nhân cần theo dõi sau xuất viện, nhưng cần external validation trước khi triển khai.
AI use:
ChatGPT được dùng để hỗ trợ viết code Python, giải thích output và kiểm tra nguy cơ data leakage. Toàn bộ code và kết quả được nhóm kiểm tra lại.
PHẦN 18: RUBRIC CHẤM ĐIỂM
| Tiêu chí | Điểm |
|---|---|
| Câu hỏi dự đoán rõ, có prediction timepoint | 1 |
| Outcome và predictors được định nghĩa đúng | 1 |
| Preprocessing hợp lý, tránh data leakage | 2 |
| Train/validation/test split đúng | 1 |
| Huấn luyện ít nhất 2 mô hình | 1 |
| Đánh giá mô hình đầy đủ: AUROC, confusion matrix, calibration | 1.5 |
| Diễn giải kết quả thận trọng, không quá mức | 1 |
| Thảo luận external validation, bias, ứng dụng lâm sàng | 1 |
| Reflection về sử dụng AI có trách nhiệm | 0.5 |
| Tổng | 10 |
PHẦN 19: THÔNG ĐIỆP KẾT THÚC
Bài 12 giúp học viên bước từ “phân tích dữ liệu” sang “xây dựng mô hình dự đoán”. Đây là vùng rất hấp dẫn, nhưng cũng nhiều bẫy.
Hãy nhớ 7 câu:
1. Machine Learning không thay thế câu hỏi nghiên cứu rõ ràng.
2. Mô hình dự đoán chỉ tốt khi dữ liệu đầu vào tốt. Garbage in, AI-flavored garbage out.
3. AUROC cao chưa đủ; cần calibration, clinical usefulness và external validation.
4. Logistic Regression vẫn là baseline mạnh, đừng khinh thường cụ già có võ.
5. Feature importance không phải bằng chứng nhân quả.
6. Mô hình chỉ nên hỗ trợ quyết định, không tự động thay thế bác sĩ hoặc quy trình chăm sóc.
7. Trước khi triển khai mô hình trong bệnh viện, phải hỏi: mô hình giúp ai, hành động gì, rủi ro nào, và ai chịu trách nhiệm?
Soạn giả: Jack Doan
Phiên bản: 1.0
- Đăng nhập để gửi ý kiến
