
🎯 MỤC TIÊU
Về kiến thức (Knowledge):
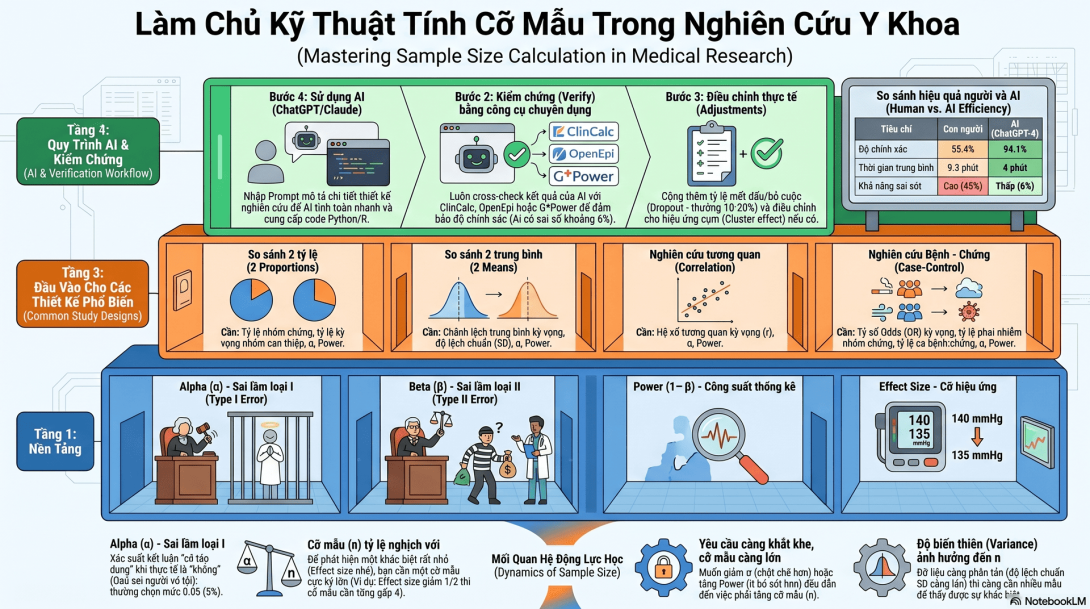
- Định nghĩa được 4 thông số cốt lõi: alpha (α), beta (β), power (1-β), và effect size
- Phân biệt được sai lầm loại I và sai lầm loại II, và hậu quả của mỗi loại
- Mô tả được cách chọn effect size phù hợp (từ literature, pilot study, hay clinical judgment)
- Hiểu được tại sao "cỡ mẫu quá lớn" cũng có vấn đề như "cỡ mẫu quá nhỏ"
Về kỹ năng (Skills): 5. Tính được cỡ mẫu cho 4 loại thiết kế phổ biến: so sánh 2 tỷ lệ, so sánh 2 trung bình, tương quan, case-control 6. Sử dụng được AI (ChatGPT) để tính cỡ mẫu nhanh chóng — và quan trọng hơn — verify kết quả 7. Sử dụng được công cụ truyền thống (ClinCalc, G*Power) để cross-check 8. Điều chỉnh được cỡ mẫu cho dropout, cluster effect, multiple testing
Về thái độ (Attitude): 9. Cẩn trọng với kết quả từ AI — luôn verify với ít nhất 2 nguồn 10. Trung thực khi cỡ mẫu cần thiết vượt quá khả năng — biết khi nào điều chỉnh nghiên cứu
📚 PHẦN 1: TẠI SAO TÍNH CỠ MẪU LẠI QUAN TRỌNG ĐẾN VẬY?
1.1. Một câu chuyện thật về 2 nghiên cứu
Hãy so sánh 2 nghiên cứu giả định nhưng dựa trên các tình huống có thật:
Nghiên cứu A: Bác sĩ Hùng làm nghiên cứu RCT tại BV tỉnh, tuyển 30 bệnh nhân mỗi nhóm. Kết quả: nhóm can thiệp có HbA1c giảm 0.5% so với nhóm chứng — p = 0.08 (không có ý nghĩa thống kê). Anh thất vọng, bài báo bị reject.
Nghiên cứu B: Bác sĩ Mai làm nghiên cứu tương tự, tuyển 2000 bệnh nhân mỗi nhóm. Kết quả: nhóm can thiệp giảm HbA1c 0.05% so với nhóm chứng — p < 0.001. Cô vui mừng, bài được đăng.
Câu hỏi: Nghiên cứu nào "thành công"?
Trả lời gây bất ngờ: Cả hai đều có vấn đề!
- Nghiên cứu A: Cỡ mẫu quá nhỏ → không đủ power để phát hiện khác biệt thực sự (0.5% là khác biệt có ý nghĩa lâm sàng!) → kết luận "không khác biệt" là sai
- Nghiên cứu B: Cỡ mẫu quá lớn → phát hiện được khác biệt 0.05% — có ý nghĩa thống kê nhưng vô nghĩa lâm sàng (HbA1c giảm 0.05% chẳng giúp ích gì cho bệnh nhân)
💡 Bài học cốt lõi: Cỡ mẫu không phải càng nhiều càng tốt. Cỡ mẫu phải vừa đủ để phát hiện khác biệt có ý nghĩa lâm sàng nếu nó tồn tại.
1.2. Tại sao đây là phần KHÓ NHẤT với học viên Việt Nam?
Theo khảo sát các khóa đào tạo nghiên cứu tại bệnh viện VN, có 3 lý do:
┌──────────────────────────────────────────────────────┐
│ 1. Toán học/thống kê đa số học viên đã quên │
│ 2. Công thức nhiều và phức tạp │
│ 3. Ít người được hướng dẫn thực sự (chỉ "copy") │
└──────────────────────────────────────────────────────┘
Kết quả: 75% học viên đánh giá biostatistics là "difficult" hoặc "very difficult". Nhiều bác sĩ chỉ "copy cỡ mẫu của bài báo trước đó" — đây là sai lầm nghiêm trọng vì mỗi nghiên cứu khác nhau.
1.3. Tin tốt: AI thay đổi cuộc chơi
Một nghiên cứu công bố năm 2024 (PowerGPT study) đã so sánh:
| Tiêu chí | Người tính | AI (ChatGPT-4) |
|---|---|---|
| Độ chính xác | 55.4% | 94.1% ✅ |
| Thời gian trung bình | 9.3 phút | 4 phút ✅ |
| Khả năng giải thích | Tùy người | Đầy đủ + code |
| Có thể sai không | Có (45% sai!) | Có (6% sai) |
💡 Tin tốt: AI rất giỏi tính cỡ mẫu — chính xác hơn cả người được đào tạo!
⚠️ Tin không tốt: AI vẫn sai 6% → vẫn phải verify bằng ít nhất 1 công cụ khác.
1.4. Hậu quả của tính sai cỡ mẫu
| Lỗi | Hậu quả |
|---|---|
| Cỡ mẫu quá nhỏ | Không phát hiện được khác biệt thực sự (Type II error). Lãng phí công sức. Bệnh nhân tham gia mà không có kết quả. |
| Cỡ mẫu quá lớn | Tốn kém không cần thiết. Đôi khi gây "hại" đạo đức (cho nhiều bệnh nhân vào nhóm placebo hơn cần thiết). Phát hiện khác biệt vô nghĩa lâm sàng. |
| Không tính cỡ mẫu | Đề tài bị reject ngay từ vòng IRB. Bài báo bị reject ở reviewer. |
✅ CHECKPOINT 1: Tự kiểm tra kiến thức
Một bác sĩ nói: "Tôi sẽ thu nhận TẤT CẢ bệnh nhân đến khoa trong 6 tháng — như vậy là khách quan và không thiên vị."
Câu nói này đúng hay sai? Vấn đề ở đâu?
Đáp án ở cuối bài.
🔬 PHẦN 2: BỐN KHÁI NIỆM CỐT LÕI — HIỂU MỘT LẦN, DÙNG MÃI
Đây là phần lý thuyết bạn PHẢI hiểu — không phải học thuộc, mà là hiểu. Tôi sẽ giải thích bằng tình huống tòa án (vì bản chất kiểm định thống kê tương tự xét xử).
2.1. Tình huống tòa án — phép ẩn dụ giúp nhớ cả đời
Tòa án: Bị cáo có tội hay không?
Mặc định: Vô tội (cho đến khi chứng minh có tội)
Quyết định: Dựa trên bằng chứng
Nghiên cứu: Can thiệp có hiệu quả hay không?
Mặc định (H₀): Không có hiệu quả (không khác biệt)
Quyết định: Dựa trên dữ liệu
Có 2 loại sai lầm trong tòa án:
┌─────────────────────────────────────────────────────────┐
│ THỰC SỰ Vô tội THỰC SỰ Có tội │
│ │
│ Tuyên Vô tội ✅ Đúng ❌ Sai loại II (β) │
│ (Thả tội phạm) │
│ │
│ Tuyên Có tội ❌ Sai loại I (α) ✅ Đúng │
│ (Oan người vô tội) │
└─────────────────────────────────────────────────────────┘
Áp dụng vào nghiên cứu:
┌─────────────────────────────────────────────────────────┐
│ THỰC SỰ Không tác THỰC SỰ Có tác dụng │
│ dụng (H₀ đúng) (H₁ đúng) │
│ │
│ Kết luận ✅ Đúng ❌ TYPE II ERROR │
│ "Không tác (β: bỏ sót thuốc tốt)│
│ dụng" │
│ │
│ Kết luận ❌ TYPE I ERROR ✅ Đúng │
│ "Có tác dụng" (α: tin nhầm │
│ thuốc rởm) │
└─────────────────────────────────────────────────────────┘
2.2. Bốn thông số cốt lõi
1️⃣ Alpha (α) — "Mức độ chấp nhận sai oan người vô tội"
Định nghĩa: Xác suất tuyên bố "có tác dụng" khi thực ra không có tác dụng (Type I error)
- Giá trị thường dùng: α = 0.05 (5%)
- Ý nghĩa: Bạn chấp nhận sai 5% lần — có thể tuyên bố có tác dụng khi thực ra không
- Khi nào dùng α nhỏ hơn (0.01)? Khi hậu quả Type I error nghiêm trọng (ví dụ: thử thuốc mới có thể gây hại)
⚠️ Lưu ý: Khi bạn làm nhiều test cùng lúc, α phải điều chỉnh nhỏ hơn (Bonferroni correction). Sẽ học ở Bài 11.
2️⃣ Beta (β) — "Mức độ chấp nhận thả tội phạm"
Định nghĩa: Xác suất tuyên bố "không tác dụng" khi thực ra CÓ tác dụng (Type II error)
- Giá trị thường dùng: β = 0.20 (20%)
- Ý nghĩa: Có 20% khả năng bỏ sót khác biệt thực sự
3️⃣ Power (1-β) — "Khả năng phát hiện khi có thực"
Định nghĩa: Xác suất phát hiện ĐÚNG sự khác biệt khi nó tồn tại = 1 - β
- Giá trị tiêu chuẩn: 80% (1 - 0.20)
- Tốt hơn: 90% (1 - 0.10) — nhưng cần cỡ mẫu lớn hơn nhiều
- Không bao giờ: < 80% — sẽ bị reviewer "đập"
💡 Mẹo nhớ: Power = "Sức mạnh" của nghiên cứu. Power cao = ít bỏ sót. Power thấp = bỏ sót nhiều.
4️⃣ Effect Size — "Độ lớn của khác biệt CÓ Ý NGHĨA"
Đây là khái niệm khó nhất và quan trọng nhất. Effect size là "khác biệt nhỏ nhất mà bạn cho rằng đáng quan tâm về mặt lâm sàng".
Ví dụ cụ thể:
- Nghiên cứu thuốc hạ huyết áp: bạn nghĩ giảm HA tâm thu 5 mmHg là có ý nghĩa lâm sàng → effect size = 5 mmHg
- Nghiên cứu thuốc giảm HbA1c: bạn nghĩ giảm 0.5% là có ý nghĩa → effect size = 0.5%
- So sánh 2 tỷ lệ: bạn nghĩ chênh lệch 15% (ví dụ 70% vs 55%) là có ý nghĩa → effect size = 15%
3 cách xác định effect size:
| Cách | Mô tả | Ưu/Nhược |
|---|---|---|
| Từ nghiên cứu trước | Tìm bài báo về can thiệp tương tự → lấy effect size đã báo cáo | ⭐ Tốt nhất, được khuyến nghị |
| Pilot study | Làm thử nghiên cứu nhỏ trước (20-30 BN) → ước lượng | ⭐ Tốt cho can thiệp mới |
| Kinh nghiệm lâm sàng | Hỏi chuyên gia/đồng nghiệp: "Khác biệt thế nào là đáng kể?" | ⚠️ Chủ quan, nhưng đôi khi cần thiết |
⚠️ Cảnh báo: KHÔNG được tính cỡ mẫu trước, rồi back-calculate ra effect size để "vừa với cỡ mẫu khả thi". Đây là gian lận khoa học.
2.3. Mối quan hệ giữa 4 thông số
Đây là điểm cực kỳ quan trọng để hiểu:
┌────────────────────────────────────────────────────────┐
│ │
│ CỠ MẪU (n) PHỤ THUỘC VÀO 4 YẾU TỐ: │
│ │
│ ↑ α nhỏ hơn (chặt chẽ hơn) ──→ ↑ n LỚN HƠN │
│ ↑ Power cao hơn (90% vs 80%) ──→ ↑ n LỚN HƠN │
│ ↓ Effect size NHỎ ──→ ↑ n LỚN HƠN (rất nhiều!) │
│ ↑ Variance (σ²) lớn ──→ ↑ n LỚN HƠN │
│ │
└────────────────────────────────────────────────────────┘
Mối quan hệ "phi tuyến" — quan trọng để biết:
Để giảm effect size một nửa → cần cỡ mẫu gấp 4 lần!
Ví dụ:
- Effect size = 1.0 → n = 64
- Effect size = 0.5 → n = 256 (gấp 4)
- Effect size = 0.25 → n = 1024 (gấp 16!)
💡 Đây là lý do chọn effect size đúng cực kỳ quan trọng — sai lầm nhỏ ở đây dẫn đến cỡ mẫu sai khủng khiếp.
✅ CHECKPOINT 2: Hiểu mối quan hệ
Một bác sĩ tính ra cần 200 bệnh nhân với power 80%, alpha 0.05. Anh ta nói: "Bệnh viện chỉ có 100 bệnh nhân, nên tôi sẽ giảm power xuống 50% để vừa với 100."
Bạn có đồng ý không? Tại sao?
Đáp án ở cuối bài.
🎯 PHẦN 3: TÍNH CỠ MẪU CHO 4 LOẠI THIẾT KẾ PHỔ BIẾN
Đây là phần "công thức". Tôi sẽ KHÔNG bắt bạn nhớ công thức (vì AI sẽ làm việc đó). Nhưng bạn cần biết cần input gì cho mỗi loại.
3.1. Cheatsheet: Cần input gì cho mỗi loại?
| Loại nghiên cứu | Input cần thiết |
|---|---|
| So sánh 2 tỷ lệ (RCT binary) | p₁, p₂, α, power, ratio (1:1?) |
| So sánh 2 trung bình (RCT continuous) | μ₁, μ₂ (hoặc difference), σ (SD), α, power |
| Tương quan | r (correlation kỳ vọng), α, power |
| Case-control | OR kỳ vọng, prevalence ở controls, ratio, α, power |
| Mô tả tỷ lệ | p kỳ vọng, độ chính xác (precision), α |
| Cohort study | Incidence ở exposed/unexposed, α, power |
| Diagnostic study | Sensitivity/specificity kỳ vọng, prevalence, precision |
3.2. Loại 1: So sánh 2 tỷ lệ (Binary outcome)
Tình huống: RCT so sánh 2 phương pháp điều trị, outcome là tỷ lệ thành công/thất bại.
Ví dụ thực tế:
"So sánh tỷ lệ kiểm soát huyết áp giữa nhóm telemedicine (kỳ vọng 70%) vs nhóm khám trực tiếp (kỳ vọng 50%). Power 80%, alpha 0.05."
Input cần:
- p₁ (tỷ lệ nhóm 1) = 70% = 0.70
- p₂ (tỷ lệ nhóm 2) = 50% = 0.50
- α = 0.05 (two-sided)
- Power = 80% = 0.80
- Ratio = 1:1
- Dropout dự kiến = 10%
Kết quả tính (bằng AI hoặc ClinCalc):
- n mỗi nhóm = 93 (chưa tính dropout)
- n mỗi nhóm = 104 (sau khi cộng 10% dropout)
- Tổng n = 208 bệnh nhân
3.3. Loại 2: So sánh 2 trung bình (Continuous outcome)
Tình huống: RCT so sánh 2 can thiệp, outcome là biến số liên tục.
Ví dụ thực tế:
"So sánh giảm điểm PSS-10 (stress) giữa nhóm MBSR và nhóm chứng. Kỳ vọng nhóm MBSR giảm 5 điểm hơn (effect size). SD = 8 điểm."
Input cần:
- Difference (μ₁ - μ₂) = 5 điểm
- SD (σ) = 8 điểm
- Cohen's d = 5/8 = 0.625 (effect size chuẩn hóa)
- α = 0.05
- Power = 80%
Kết quả: n mỗi nhóm ≈ 41 → tổng 82 + dropout
💡 Cohen's d (rule of thumb):
- 0.2 = nhỏ (cần cỡ mẫu lớn)
- 0.5 = trung bình
- 0.8 = lớn (cỡ mẫu nhỏ vẫn đủ)
3.4. Loại 3: Tương quan (Correlation)
Tình huống: Nghiên cứu mối tương quan giữa 2 biến liên tục.
Ví dụ thực tế:
"Tương quan giữa BMI và HbA1c ở bệnh nhân ĐTĐ. Kỳ vọng r = 0.3. Power 80%, alpha 0.05."
Input cần:
- r kỳ vọng = 0.3
- α = 0.05 (two-sided)
- Power = 80%
Kết quả: n ≈ 84
💡 Cohen's correlation: r = 0.1 (nhỏ), 0.3 (trung bình), 0.5 (lớn)
3.5. Loại 4: Case-Control
Tình huống: Nghiên cứu yếu tố nguy cơ — so sánh ca bệnh và ca không bệnh.
Ví dụ thực tế:
"Hút thuốc có phải yếu tố nguy cơ ung thư phổi không? Kỳ vọng OR = 2.5. Tỷ lệ hút thuốc ở nhóm chứng = 30%. Tỷ lệ ca:chứng = 1:1."
Input cần:
- OR kỳ vọng = 2.5
- Prevalence of exposure ở controls = 0.30
- Tỷ lệ case:control (1:1, 1:2, 1:3?)
- α = 0.05, power = 80%
Kết quả: ~75 cases và 75 controls
3.6. Bảng tham khảo nhanh (cho cảm giác về cỡ mẫu)
Đây là bảng "cảm giác" giúp bạn ước lượng nhanh:
| Loại | Effect size nhỏ | Effect size TB | Effect size lớn |
|---|---|---|---|
| 2 tỷ lệ (5% diff) | ~600/nhóm | ~150/nhóm | ~50/nhóm |
| 2 trung bình (Cohen's d) | d=0.2: ~400/nhóm | d=0.5: ~64/nhóm | d=0.8: ~26/nhóm |
| Correlation | r=0.1: ~780 | r=0.3: ~84 | r=0.5: ~30 |
| Case-control (OR) | OR=1.5: ~250/nhóm | OR=2.5: ~75/nhóm | OR=4: ~30/nhóm |
💡 Bài học: Effect size nhỏ → cỡ mẫu KHỔNG LỒ. Đây là lý do nhiều nghiên cứu RCT đa trung tâm cần hàng nghìn bệnh nhân.
✅ CHECKPOINT 3: Áp dụng
Cho 4 tình huống, bạn cần input gì?
- "Tôi muốn xem can thiệp giáo dục có giảm tỷ lệ không tuân thủ thuốc không" → Loại nào? Cần input gì?
- "Tôi muốn xem mối liên hệ giữa thời gian ngủ và điểm stress" → Loại nào?
- "Tôi muốn so sánh thời gian nằm viện giữa 2 phác đồ điều trị viêm phổi" → Loại nào?
Đáp án ở cuối bài.
🤖 PHẦN 4: SỬ DỤNG AI ĐỂ TÍNH CỠ MẪU — CHÍNH XÁC VÀ NHANH
4.1. Tại sao AI rất giỏi ở khâu này?
AI (đặc biệt là ChatGPT/Claude) xuất sắc ở 4 việc:
- Hiểu natural language — bạn mô tả bằng tiếng Việt, AI vẫn hiểu
- Chọn đúng công thức — AI biết khi nào dùng công thức nào
- Sinh code Python/R — bạn có thể chạy lại, kiểm tra
- Giải thích kết quả — bao gồm cả interpretation
4.2. Quy trình 5 bước với AI
BƯỚC 1: Mô tả nghiên cứu rõ ràng cho AI (loại, outcome, expected values)
↓
BƯỚC 2: Yêu cầu AI tính cỡ mẫu + sinh code Python
↓
BƯỚC 3: Đọc kỹ kết quả + interpretation
↓
BƯỚC 4: VERIFY bằng công cụ thứ 2 (ClinCalc/G*Power) ← QUAN TRỌNG!
↓
BƯỚC 5: Sensitivity analysis: thử các effect size khác nhau
4.3. Prompt mẫu CHUẨN (sao chép, dùng được ngay)
Prompt 1: So sánh 2 tỷ lệ (RCT)
Tôi cần tính cỡ mẫu cho RCT.
Thông tin nghiên cứu:
- Thiết kế: RCT 2 nhánh song song, phân ngẫu nhiên 1:1
- Outcome chính: Tỷ lệ kiểm soát huyết áp đạt mục tiêu sau 6 tháng (binary)
- Tỷ lệ kỳ vọng nhóm chứng: 50% (dựa trên dữ liệu BV chúng tôi)
- Tỷ lệ kỳ vọng nhóm can thiệp: 70% (dựa trên RCT của Smith 2023)
- Alpha: 0.05 (two-sided)
- Power: 80%
- Dropout dự kiến: 15% (BV tuyến tỉnh, BN khó theo dõi)
Hãy:
1. Tính cỡ mẫu mỗi nhóm và tổng
2. Bao gồm điều chỉnh dropout
3. Cung cấp Python code có thể chạy lại
4. Giải thích interpretation của kết quả
5. Đề xuất sensitivity analysis: nếu effect khác (ví dụ p1=65% thay vì 70%) thì n bao nhiêu?
Comments code bằng tiếng Việt.
Prompt 2: So sánh 2 trung bình
Tính cỡ mẫu cho nghiên cứu can thiệp.
Thông tin:
- Thiết kế: RCT 2 nhánh, randomization 1:1
- Outcome: Thay đổi điểm PSS-10 (stress scale) sau 8 tuần
- Effect size kỳ vọng (chênh lệch trung bình): 5 điểm
- SD kỳ vọng: 8 điểm (từ Vietnamese validation study của PSS-10)
- Alpha: 0.05 (two-sided)
- Power: 80%
- Dropout: 20%
Hãy:
1. Tính Cohen's d
2. Tính cỡ mẫu (mỗi nhóm + tổng + sau dropout)
3. Python code dùng statsmodels hoặc scipy
4. Sensitivity: nếu SD thực tế là 10 thay vì 8 thì sao?
5. Khuyến nghị: cỡ mẫu này có khả thi với BV ~30 BN/tháng không?
Comments tiếng Việt.
Prompt 3: Correlation study
Tôi muốn nghiên cứu tương quan giữa BMI và HbA1c ở bệnh nhân ĐTĐ
type 2 tại BV của tôi.
Thông tin:
- Tương quan kỳ vọng: r = 0.3 (từ meta-analysis 2022)
- Alpha: 0.05
- Power: 80%
Hãy:
1. Tính cỡ mẫu cần thiết
2. Tính sensitivity: r = 0.2, 0.25, 0.35 thì n bao nhiêu?
3. Python code (scipy.stats hoặc pingouin)
4. Lưu ý gì khi dùng Pearson vs Spearman?
Trình bày dạng bảng so sánh.
Prompt 4: Case-control study
Nghiên cứu yếu tố nguy cơ ung thư phổi ở phụ nữ Việt Nam (không hút
thuốc) — phơi nhiễm là đun bếp than/củi.
Thông tin:
- Thiết kế: Case-control
- OR kỳ vọng: 2.5 (từ Tian 2014, China)
- Prevalence of exposure ở controls: 30%
- Ratio case:control: 1:2 (vì ca bệnh khó tuyển)
- Alpha: 0.05, Power: 80%
Hãy:
1. Tính số cases và controls cần thiết
2. So sánh nếu ratio 1:1 vs 1:2 vs 1:3 - cái nào hiệu quả hơn?
3. Python code
4. Discussion: ratio bao nhiêu là tối ưu cho nghiên cứu của tôi?
Trình bày dạng bảng.
4.4. ⚠️ 5 cảnh báo khi dùng AI tính cỡ mẫu
Cảnh báo 1: AI có thể chọn SAI công thức
AI có thể nhầm:
- Chi-square test vs Fisher's exact test
- Independent t-test vs paired t-test
- Pearson vs Spearman correlation
Phòng tránh: Trong prompt, mô tả rõ thiết kế — paired hay không, parametric hay non-parametric.
Cảnh báo 2: AI có thể "ảo tưởng" effect size
Đôi khi AI sẽ tự "đoán" effect size nếu bạn không cung cấp. Ví dụ AI nói: "Cohen's d = 0.5 thường được dùng..." — đây có thể không đúng cho nghiên cứu của bạn.
Phòng tránh: LUÔN cung cấp effect size với nguồn (literature/pilot/clinical judgment).
Cảnh báo 3: AI có thể quên dropout
Nhiều khi AI tính cỡ mẫu "thuần", quên cộng dropout.
Phòng tránh: Yêu cầu rõ "tính cả dropout X%".
Cảnh báo 4: Code có thể có bug
Mặc dù AI viết code đa số đúng, vẫn có thể có lỗi tinh tế.
Phòng tránh: VERIFY bằng công cụ thứ 2 (xem 4.5).
Cảnh báo 5: AI không biết khả thi của BV bạn
AI nói: "Cần 500 bệnh nhân" — nhưng BV bạn chỉ có 20/tháng.
Phòng tránh: Sau khi có kết quả, hỏi AI: "Với BV ~20 BN/tháng và 12 tháng, n=240 — có đủ không? Nếu không, tôi nên điều chỉnh gì?"
4.5. VERIFY — bước KHÔNG ĐƯỢC bỏ qua
Quy tắc vàng: "Tính cỡ mẫu bằng AI là 90%. Verify là 10% còn lại — nhưng quan trọng nhất."
3 công cụ verify miễn phí:
| Công cụ | Link | Ưu điểm |
|---|---|---|
| ClinCalc | https://clincalc.com/stats/samplesize.aspx | Dễ dùng nhất, có nhiều loại |
| OpenEpi | https://www.openepi.com | Toàn diện, có epidemiology tools |
| G*Power | https://www.psychologie.hhu.de/arbeitsgruppen/allgemeine-psychologie-und-arbeitspsychologie/gpower | Vàng tiêu chuẩn, miễn phí, cần cài |
Nếu kết quả AI và công cụ verify khác nhau:
- Sai số <10% → OK (do làm tròn, công thức)
- Sai số 10-30% → Kiểm tra lại input
- Sai số >30% → AI có thể sai công thức, hỏi lại AI hoặc dùng kết quả tool
✅ CHECKPOINT 4
ChatGPT trả lời bạn: "Cần 145 bệnh nhân mỗi nhóm."
Bạn verify bằng ClinCalc → kết quả: 152 bệnh nhân mỗi nhóm.
Bạn nên: a) Tin AI, vì AI thông minh hơn
b) Tin ClinCalc, vì là công cụ chuyên dụng
c) Lấy giá trị lớn hơn (152) cho an toàn
d) Lấy trung bình (148.5)
Đáp án ở cuối bài.
📐 PHẦN 5: ĐIỀU CHỈNH CỠ MẪU — CÁC TÌNH HUỐNG ĐẶC BIỆT
5.1. Điều chỉnh cho Dropout
Công thức điều chỉnh:
n_điều_chỉnh = n_tính_toán / (1 - dropout_rate)
Ví dụ:
- n tính toán = 100 mỗi nhóm
- Dropout dự kiến = 20%
- n cần tuyển = 100 / (1 - 0.20) = 100 / 0.80 = 125 mỗi nhóm
Cách ước lượng dropout:
- RCT 6 tháng: 10-15%
- RCT 1 năm: 20-30%
- RCT 2 năm trở lên: 30-50%
- Tại VN: cộng thêm 5-10% (BN khó theo dõi do địa lý, thay đổi địa chỉ)
5.2. Điều chỉnh cho Cluster Effect
Khi nào áp dụng? Khi randomization theo cụm (ví dụ: theo bệnh viện, khoa, làng) thay vì theo cá nhân.
Design Effect (DE) = 1 + (m-1) × ICC
- m = số đối tượng trong mỗi cụm
- ICC = Intraclass Correlation Coefficient (thường 0.01-0.05 trong y khoa)
Ví dụ:
- n cá nhân = 200
- 10 cụm, mỗi cụm 20 người, ICC = 0.02
- DE = 1 + (20-1) × 0.02 = 1.38
- n cluster = 200 × 1.38 = 276 người
💡 Cluster RCT luôn cần cỡ mẫu lớn hơn individual RCT. Đừng quên!
5.3. Điều chỉnh cho Multiple Testing
Khi bạn test nhiều outcomes hoặc nhiều subgroups, α phải điều chỉnh nhỏ hơn.
Bonferroni correction (đơn giản nhất):
α_điều_chỉnh = α / số_test
Ví dụ:
- Bạn có 5 outcomes chính
- α gốc = 0.05
- α điều chỉnh = 0.05 / 5 = 0.01
- → Cỡ mẫu cần lớn hơn (vì α nhỏ hơn)
5.4. Khi cỡ mẫu cần thiết VƯỢT QUÁ khả năng — làm gì?
Đây là tình huống rất phổ biến ở VN. Bạn có 4 lựa chọn:
| Lựa chọn | Khi nào dùng | Lưu ý |
|---|---|---|
| 1. Tăng effect size kỳ vọng | Có cơ sở lâm sàng để tin effect lớn hơn | KHÔNG được "ép" để vừa cỡ mẫu — vô đạo đức |
| 2. Giảm power (80% → 70%) | Pilot study, exploratory | Phải báo cáo rõ trong limitations |
| 3. Multi-center collaboration | Nghiên cứu lớn | Tăng cỡ mẫu nhưng phức tạp logistic |
| 4. Đổi thiết kế | Nghiên cứu mô tả thay vì can thiệp | Đôi khi đây là lựa chọn đúng |
💡 Trung thực là tốt nhất: Nếu bạn không thể đạt cỡ mẫu cần thiết, hãy báo cáo rõ trong limitations thay vì che giấu. Reviewer sẽ tôn trọng sự trung thực.
💻 PHẦN 6: THỰC HÀNH (60 phút)
6.1. Chuẩn bị (5 phút)
- [ ] Mở ChatGPT (hoặc Claude)
- [ ] Mở ClinCalc.com trong tab khác
- [ ] Có giấy bút để ghi kết quả
6.2. Thực hành 1: RCT so sánh 2 tỷ lệ (15 phút)
Tình huống: "So sánh tỷ lệ kiểm soát huyết áp giữa nhóm telemedicine (kỳ vọng 70%) vs nhóm khám trực tiếp (kỳ vọng 50%). Power 80%, alpha 0.05, dropout 15%, ratio 1:1."
Bước 1 (3 phút): Sao chép Prompt 1 ở Phần 4.3 vào ChatGPT, điều chỉnh thông số nếu muốn.
Bước 2 (3 phút): Đọc kỹ kết quả:
- n mỗi nhóm = ?
- Tổng n = ?
- AI có cộng dropout chưa?
Bước 3 (5 phút): Verify bằng ClinCalc:
- Vào https://clincalc.com/stats/samplesize.aspx
- Chọn "Dichotomous (Two Independent Sample)"
- Nhập: Anticipated incidence Group 1 = 50, Group 2 = 70
- Power = 80, Alpha = 0.05, Enrollment ratio = 1
- So sánh kết quả với AI
Bước 4 (4 phút): Sensitivity analysis — thử các giá trị:
- Nếu p₁ = 60% thay vì 70% (effect nhỏ hơn) → n = ?
- Nếu power = 90% thay vì 80% → n = ?
- Nếu dropout = 25% thay vì 15% → n = ?
Bạn nhận ra gì về sự nhạy cảm của n?
6.3. Thực hành 2: Correlation study (10 phút)
Tình huống: "Nghiên cứu tương quan giữa BMI và HbA1c. Kỳ vọng r = 0.3."
Bước 1: Dùng Prompt 3 ở Phần 4.3 → ghi kết quả
Bước 2: Verify bằng OpenEpi:
- Vào https://www.openepi.com → Sample Size → Mean
- Hoặc Google: "sample size correlation calculator"
- Nhập r = 0.3, alpha = 0.05, power = 0.80
Bước 3: Câu hỏi suy nghĩ:
- Nếu r thực tế nhỏ hơn (r = 0.2), bạn có detect được không với cỡ mẫu hiện tại?
- Nếu nghiên cứu chỉ có thể tuyển 50 bệnh nhân, power thực tế là bao nhiêu?
6.4. Thực hành 3: Case-control (10 phút)
Tình huống: "Nghiên cứu yếu tố nguy cơ — kỳ vọng OR=2.5, prevalence exposure ở controls=30%."
Bước 1: Dùng Prompt 4 → ghi kết quả với 3 ratio: 1:1, 1:2, 1:3
Bước 2: Trả lời:
- Tổng cỡ mẫu cao nhất ở ratio nào?
- Số CASES thấp nhất ở ratio nào?
- Nếu cases khó tuyển, bạn chọn ratio nào?
6.5. Thực hành 4: Câu hỏi nghiên cứu của BẠN (15 phút)
Đây là phần quan trọng nhất — áp dụng cho nghiên cứu thực của bạn.
Bước 1 (5 phút): Lấy câu hỏi PICO bạn đã viết ở Bài 5. Xác định:
- Loại nghiên cứu? (RCT, cohort, case-control, cross-sectional?)
- Outcome chính là gì? (binary, continuous, time-to-event?)
- Effect size kỳ vọng là bao nhiêu? (Có nguồn gốc từ đâu?)
Bước 2 (5 phút): Viết prompt cho AI dựa trên template ở Phần 4.3, điền thông tin của bạn.
Bước 3 (3 phút): Verify bằng công cụ thứ 2.
Bước 4 (2 phút): Đánh giá khả thi:
- BV của bạn có ~ bao nhiêu bệnh nhân thuộc tiêu chuẩn lựa chọn / tháng?
- Bạn có bao nhiêu tháng cho thu thập dữ liệu?
- Có đủ không? Nếu không, bạn sẽ điều chỉnh gì?
📋 Sản phẩm cuối: Một đoạn 100-200 từ về sample size cho proposal của bạn — bao gồm thông số, kết quả, và justification.
📋 PHẦN 7: CHECKLIST KIẾN THỨC SAU BÀI HỌC
Kiến thức cốt lõi
- [ ] Phân biệt được Type I error (α) và Type II error (β)
- [ ] Hiểu Power = 1-β và tại sao thường chọn 80%
- [ ] Định nghĩa được effect size và 3 cách xác định
- [ ] Hiểu mối quan hệ giữa α, power, effect size, và n
- [ ] Biết khi nào cần điều chỉnh cho dropout, cluster, multiple testing
Kỹ năng thực hành
- [ ] Đã viết được prompt rõ ràng cho AI
- [ ] Đã tính cỡ mẫu cho ít nhất 2 loại thiết kế khác nhau
- [ ] Đã verify kết quả bằng ClinCalc/OpenEpi
- [ ] Đã làm sensitivity analysis với nhiều giá trị effect size
- [ ] Đã tính cỡ mẫu cho nghiên cứu thực của bản thân
Thái độ
- [ ] Luôn verify kết quả AI bằng công cụ thứ 2
- [ ] Trung thực khi cỡ mẫu cần thiết vượt khả năng
- [ ] Không "ép" effect size để vừa cỡ mẫu khả thi
📖 PHẦN 8: CÂU HỎI THẢO LUẬN
Câu hỏi cá nhân:
- Trong nghiên cứu của bạn, bạn lấy effect size từ đâu? Nguồn có đáng tin không?
- BV của bạn có đủ bệnh nhân để đạt cỡ mẫu cần thiết không? Nếu không, làm gì?
- Bạn có sẵn sàng giảm power xuống 70% nếu không thể đạt 80%? Khi nào?
Câu hỏi nhóm:
- Tại VN, có bao nhiêu bài báo bạn đọc có báo cáo rõ ràng sample size justification? Tại sao tỷ lệ này thấp?
- Khi BV nhỏ, có nên hợp tác multi-center không? Ưu/nhược điểm?
- Tỷ lệ dropout 30% có chấp nhận được không? Phụ thuộc vào gì?
Câu hỏi phản biện:
- Có nên báo cáo "post-hoc power analysis" sau khi nghiên cứu xong không? (Gợi ý: hầu hết tạp chí KHÔNG khuyến khích — tại sao?)
- AI tính cỡ mẫu nhanh hơn người, nhưng có làm con người lười suy nghĩ về thiết kế không? Làm sao tránh?
- Trong tình huống "không có tiền lệ" (effect size không biết), bạn xử lý thế nào?
📚 TÀI LIỆU THAM KHẢO BÀI 8
Sách giáo khoa
- Chow, S. C., Shao, J., Wang, H., & Lokhnygina, Y. (2017). Sample Size Calculations in Clinical Research (3rd ed.). Chapman and Hall/CRC. (Sách kinh điển)
- Cohen, J. (1988). Statistical Power Analysis for the Behavioral Sciences (2nd ed.). Lawrence Erlbaum Associates. (Bản gốc về effect size)
- Hulley, S. B., et al. (2013). Designing Clinical Research (4th ed.) — Chapter 6: Estimating Sample Size and Power. Lippincott.
Bài báo khoa học chính
- Bacchetti, P. (2010). Current sample size conventions: Flaws, harms, and alternatives. BMC Medicine, 8, 17.
- Schulz, K. F., & Grimes, D. A. (2005). Sample size calculations in randomised trials: mandatory and mystical. The Lancet, 365(9467), 1348-1353.
- PowerGPT paper (2024): "Large Language Models for Sample Size Calculations" — chứng minh accuracy 94.1% của AI
Hướng dẫn quốc tế
- CONSORT 2025 Statement — Item 7a: yêu cầu báo cáo sample size calculation chi tiết
- SPIRIT 2013 Statement — yêu cầu sample size cho protocol
Công cụ tính (miễn phí)
- ClinCalc: https://clincalc.com/stats/samplesize.aspx
- OpenEpi: https://www.openepi.com
- G*Power: https://www.psychologie.hhu.de/arbeitsgruppen/allgemeine-psychologie-und-arbeitspsychologie/gpower
- Sealed Envelope: https://www.sealedenvelope.com (cho RCT)
- WHO Sample Size: http://tools.who.int/sample-size
Khóa học online
- Coursera — "Power, Sample Size, and Confidence Intervals" (Johns Hopkins)
- YouTube — StatQuest: "Power Analysis, Clearly Explained" (free, dễ hiểu)
- edX — "Statistical Inference and Modeling" (Harvard)
Bối cảnh Việt Nam
- Đại học Y Hà Nội. (2020). Phương pháp NCKH Y học — Chương: Tính cỡ mẫu
- Tạp chí Y học Việt Nam — Hướng dẫn tác giả về báo cáo sample size
✅ ĐÁP ÁN CÁC CHECKPOINT
Checkpoint 1:
Câu nói SAI — Đây là sai lầm rất phổ biến!
Vấn đề:
- Không có cơ sở khoa học — không tính cỡ mẫu = không biết power. Có thể quá nhỏ (Type II error) hoặc quá lớn (lãng phí).
- Không phải "không thiên vị" — vấn đề thiên vị là selection bias (cách chọn mẫu), KHÔNG phải số lượng.
- IRB/tạp chí sẽ reject — đề tài không có sample size justification = không được thông qua.
- Không thể publish — CONSORT yêu cầu báo cáo sample size calculation.
Đúng: Phải tính trước cỡ mẫu cần thiết, rồi tuyển đến khi đủ (hoặc dừng theo kế hoạch interim analysis).
Checkpoint 2:
KHÔNG đồng ý — Đây là cách tiếp cận rất sai.
Vấn đề:
- Power 50% nghĩa là bạn có 50% khả năng bỏ sót khác biệt thực sự — như tung đồng xu!
- IRB và reviewer sẽ reject ngay
- Nguy hại đạo đức: đưa 100 bệnh nhân vào nghiên cứu mà nửa khả năng không phát hiện được kết quả → lãng phí thời gian/công sức của họ
Đúng: Bác sĩ nên:
- Xem xét lại effect size — có cơ sở để tin effect lớn hơn không?
- Multi-center collaboration để tăng n
- Đổi sang pilot study (báo cáo rõ là pilot, không kỳ vọng power 80%)
- Đổi câu hỏi nghiên cứu sang câu hỏi mô tả
Checkpoint 3:
- So sánh 2 tỷ lệ (RCT binary) — input: tỷ lệ không tuân thủ trong 2 nhóm, α, power, dropout
- Correlation study — input: r kỳ vọng, α, power. Lưu ý: Pearson nếu cả 2 biến phân phối chuẩn, Spearman nếu không.
- So sánh 2 trung bình — input: chênh lệch trung bình kỳ vọng, SD, α, power. Có thể cần làm pilot trước để ước lượng SD.
Checkpoint 4:
Đáp án đúng: c) Lấy giá trị lớn hơn (152) cho an toàn
Lý do:
- Sai số ~5% giữa 2 công cụ là bình thường (do làm tròn, công thức hơi khác)
- Lấy giá trị lớn hơn → đảm bảo power ≥ 80% (an toàn)
- Lấy trung bình (148.5) → không có cơ sở khoa học, chưa từng được khuyến nghị
- Tin AI hoặc tin tool một cách "mù quáng" — không nên
Lưu ý: Nếu sai số > 30%, KHÔNG nên lấy giá trị lớn hơn — phải xem lại có lỗi nhập input không, có chọn đúng test không, v.v.
🎓 KẾT LUẬN BÀI 8
Chúc mừng bạn đã hoàn thành Bài 8 — bài có nội dung toán học/thống kê khó nhất cho đến giờ. Hãy nhớ ba thông điệp cốt lõi:
💡 Thông điệp 1: Cỡ mẫu không phải càng nhiều càng tốt. Cỡ mẫu phải vừa đủ để phát hiện khác biệt có ý nghĩa lâm sàng nếu nó tồn tại — không hơn không kém. Tính sai cỡ mẫu là "bước đầu tiên đi vào ngõ cụt" của nghiên cứu.
💡 Thông điệp 2: AI là siêu trợ thủ cho tính cỡ mẫu — chính xác hơn cả người được đào tạo (94.1% vs 55.4%). Nhưng AI vẫn sai 6% → LUÔN VERIFY bằng ClinCalc/OpenEpi/G*Power. Hai nguồn đồng ý mới tin được.
💡 Thông điệp 3: Trung thực với chính mình về khả thi. Nếu cỡ mẫu cần thiết vượt khả năng BV, đừng ép effect size — hãy điều chỉnh thiết kế hoặc collaborate. Reviewer tôn trọng sự trung thực hơn là kết quả "đẹp".
Soạn giả: Jack
Phiên bản: 1.0 (2026)
Liên hệ: thaihoadoanbrvt@gmail.com
Phản hồi: Mọi góp ý xin gửi về email
"To call in the statistician after the experiment is done may be no more than asking him to perform a postmortem examination: he may be able to say what the experiment died of."
— Sir Ronald A. Fisher (cha đẻ của thống kê hiện đại)("Mời chuyên gia thống kê SAU KHI thí nghiệm xong cũng giống như mời họ khám tử thi: họ chỉ có thể nói thí nghiệm của bạn ĐÃ CHẾT vì lý do gì.")
Đó là lý do tính cỡ mẫu phải làm TRƯỚC, không phải sau.
- Đăng nhập để gửi ý kiến
