
🎯 MỤC TIÊU
Về kiến thức:
- Phân biệt được thống kê mô tả và thống kê suy luận.
- Mô tả được biến định lượng bằng mean ± SD hoặc median, IQR.
- Mô tả được biến định tính bằng tần số và tỷ lệ phần trăm.
- Chọn được test thống kê phù hợp theo loại biến, số nhóm và phân phối dữ liệu.
- Hiểu ý nghĩa của p-value, khoảng tin cậy 95%, effect size và odds ratio.
- Hiểu vai trò của hồi quy tuyến tính và hồi quy logistic trong nghiên cứu y khoa.
Về kỹ năng:
- Tạo được Table 1 mô tả đặc điểm nền của đối tượng nghiên cứu.
- So sánh được biến định lượng giữa 2 nhóm hoặc nhiều nhóm.
- So sánh được biến định tính bằng Chi-square hoặc Fisher’s exact test.
- Phân tích được tương quan Pearson/Spearman.
- Chạy được mô hình hồi quy logistic cơ bản.
- Dùng AI để viết code SPSS/Python/R và kiểm tra giả định thống kê.
- Diễn giải được kết quả thống kê bằng ngôn ngữ phù hợp cho báo cáo khoa học.
Về thái độ:
- Không chọn test theo cảm tính hoặc theo thói quen “cứ p < 0,05 là vui”.
- Không để AI quyết định thay hoàn toàn kế hoạch phân tích.
- Biết kiểm chứng kết quả AI, nhất là khi AI viết code hoặc diễn giải số liệu.
- Tôn trọng nguyên tắc phân tích đã định trước trong đề cương, tránh “p-hacking” — tức là đào dữ liệu như đào kho báu, thấy p đẹp thì reo.
Nếu dữ liệu chưa sạch mà đem phân tích, kết quả có thể rất “ấn tượng” nhưng sai.
Raw data
↓
Data cleaning
↓
Analysis-ready dataset
↓
Descriptive statistics
↓
Inferential statistics
↓
Interpretation
↓
Tables and Results section
Thông điệp chính:
Phân tích thống kê không phải là bấm nút để ra p-value. Phân tích thống kê là quá trình biến dữ liệu thành bằng chứng có thể tin được.
PHẦN 1: THỐNG KÊ MÔ TẢ VÀ THỐNG KÊ SUY LUẬN
1.1. Thống kê mô tả là gì?
Thống kê mô tả dùng để mô tả dữ liệu hiện có.
Nó trả lời các câu hỏi:
- Mẫu nghiên cứu gồm bao nhiêu người?
- Tuổi trung bình là bao nhiêu?
- Bao nhiêu phần trăm là nữ?
- HbA1c trung bình là bao nhiêu?
- Tỷ lệ tăng huyết áp đi kèm là bao nhiêu?
- Nhóm điều trị A và B có giống nhau ở baseline không?
Ví dụ:
Trong 200 bệnh nhân đái tháo đường type 2, tuổi trung bình là 58,4 ± 10,2 tuổi; 54% là nữ; HbA1c trung vị là 8,1% với IQR 7,2–9,4%.
Thống kê mô tả chưa kết luận “có khác biệt thật sự” hay “có liên quan thật sự”. Nó chỉ mô tả bức tranh dữ liệu.
1.2. Thống kê suy luận là gì?
Thống kê suy luận dùng dữ liệu từ mẫu để suy luận về quần thể lớn hơn.
Nó trả lời các câu hỏi:
- Hai nhóm có khác nhau có ý nghĩa thống kê không?
- Can thiệp có làm giảm HbA1c không?
- BMI có liên quan với HbA1c không?
- Nhóm điều trị A có tăng khả năng đạt HbA1c < 7% không?
- Sau khi hiệu chỉnh tuổi, giới, BMI, kết quả còn khác biệt không?
Ví dụ:
Sau 12 tuần, mức giảm HbA1c trung bình ở nhóm can thiệp cao hơn nhóm chứng 0,6%, với p = 0,02 và khoảng tin cậy 95% từ 0,1 đến 1,1%.
1.3. Cách nhớ đơn giản
| Loại thống kê | Câu hỏi chính | Ví dụ |
|---|---|---|
| Thống kê mô tả | Dữ liệu của tôi trông như thế nào? | Tuổi trung bình, tỷ lệ nữ, median HbA1c |
| Thống kê suy luận | Khác biệt/liên quan này có thể tồn tại ngoài mẫu không? | t-test, Chi-square, hồi quy |
Ẩn dụ nhỏ:
Thống kê mô tả là chụp ảnh lớp học. Thống kê suy luận là đoán xem toàn trường có giống lớp đó không. Đoán thì phải có phương pháp, không phải nhìn vài bạn ngồi bàn đầu rồi kết luận cả trường học giỏi toán.
PHẦN 2: HIỂU LOẠI BIẾN TRƯỚC KHI CHỌN TEST
Muốn chọn test đúng, trước hết phải biết biến của mình thuộc loại nào.
2.1. Biến định lượng — Continuous/Numeric Variables
Là biến có giá trị số, thường đo được trên thang liên tục.
Ví dụ:
- Tuổi.
- BMI.
- HbA1c.
- Huyết áp tâm thu.
- Huyết áp tâm trương.
- Thời gian mắc bệnh.
- Điểm stress.
- Thời gian nằm viện.
Cách mô tả biến định lượng
| Phân phối | Cách báo cáo |
|---|---|
| Gần chuẩn | Mean ± SD |
| Lệch nhiều | Median, IQR |
| Có outlier mạnh | Median, IQR thường an toàn hơn |
Ví dụ:
Age: 58.4 ± 10.2 years
HbA1c: 8.1% (IQR: 7.2–9.4)
Length of stay: 6 days (IQR: 4–9)
2.2. Biến định tính — Categorical Variables
Là biến chia thành nhóm.
Ví dụ:
- Giới tính: nam/nữ.
- Hút thuốc: có/không.
- Nhóm điều trị: A/B.
- Mức độ bệnh: nhẹ/trung bình/nặng.
- Đạt HbA1c < 7%: có/không.
- Có tăng huyết áp: có/không.
Cách mô tả biến định tính
Dùng n (%).
Ví dụ:
Female: 108 (54.0%)
Hypertension: 126 (63.0%)
Current smoking: 34 (17.0%)
HbA1c target achieved: 72 (36.0%)
2.3. Biến thứ bậc — Ordinal Variables
Là biến phân nhóm có thứ tự.
Ví dụ:
- Mức đau: nhẹ/trung bình/nặng.
- Mức độ hài lòng: rất không hài lòng → rất hài lòng.
- NYHA class I–IV.
- Giai đoạn bệnh thận mạn.
Biến thứ bậc dễ gây nhầm vì nhìn giống categorical nhưng có thứ tự. Không nên xử lý tùy tiện như biến liên tục nếu không có lý do hợp lý.
PHẦN 3: KIỂM TRA PHÂN PHỐI DỮ LIỆU
3.1. Vì sao phải kiểm tra phân phối?
Nhiều test thống kê giả định dữ liệu có phân phối gần chuẩn. Nếu dữ liệu lệch nhiều mà vẫn dùng test tham số, kết quả có thể không phù hợp.
Ví dụ:
- Tuổi thường gần chuẩn.
- Thời gian nằm viện thường lệch phải.
- Chi phí điều trị thường lệch rất mạnh.
- CRP, D-dimer, triglyceride có thể lệch.
3.2. Cách kiểm tra phân phối
Có 3 cách chính:
- Nhìn biểu đồ histogram.
- Nhìn Q-Q plot.
- Dùng test Shapiro-Wilk hoặc Kolmogorov-Smirnov.
Lưu ý quan trọng
Không nên chỉ dựa vào Shapiro-Wilk. Với cỡ mẫu lớn, test này rất dễ cho p < 0,05 dù dữ liệu chỉ lệch nhẹ. Hãy kết hợp:
Histogram + Q-Q plot + hiểu biết lâm sàng + cỡ mẫu
3.3. Prompt AI kiểm tra phân phối
Tôi có dataset nghiên cứu y khoa với các biến định lượng:
Age, BMI, HbA1c, SBP, DBP, Duration_DM.
Hãy viết code Python để:
1. Tính mean, SD, median, IQR, min, max
2. Vẽ histogram cho từng biến
3. Vẽ Q-Q plot
4. Chạy Shapiro-Wilk test
5. Đề xuất biến nào nên báo cáo bằng mean±SD và biến nào nên báo cáo bằng median(IQR)
Yêu cầu:
- Code có comment bằng tiếng Việt
- Không tự loại outlier
- In kết quả thành bảng rõ ràng
PHẦN 4: TABLE 1 — BẢNG ĐẶC ĐIỂM NỀN
Theo khung chương trình gốc, thực hành đầu tiên của Bài 11 là tạo Table 1 — Baseline Characteristics, so sánh đặc điểm nền giữa hai nhóm Treatment A và Treatment B, gồm biến định lượng như tuổi, BMI, HbA1c, thời gian mắc đái tháo đường, và biến định tính như giới, tăng huyết áp, hút thuốc.
4.1. Table 1 là gì?
Table 1 là bảng đầu tiên trong hầu hết bài báo y khoa định lượng. Nó mô tả đối tượng nghiên cứu.
Table 1 thường trả lời:
- Mẫu nghiên cứu có đặc điểm gì?
- Hai nhóm có cân bằng ở thời điểm ban đầu không?
- Có yếu tố nào khác biệt giữa nhóm can thiệp và nhóm chứng không?
- Người đọc có thể đánh giá tính khái quát của nghiên cứu không?
4.2. Cấu trúc Table 1 mẫu
| Variable | Total (n=200) | Treatment A (n=100) | Treatment B (n=100) | p-value |
|---|---|---|---|---|
| Age, mean ± SD | 58.4 ± 10.2 | 57.9 ± 9.8 | 58.9 ± 10.6 | 0.48 |
| Female, n (%) | 108 (54.0) | 52 (52.0) | 56 (56.0) | 0.57 |
| BMI, mean ± SD | 24.8 ± 3.1 | 24.5 ± 3.0 | 25.1 ± 3.2 | 0.18 |
| HbA1c, median (IQR) | 8.1 (7.2–9.4) | 8.2 (7.3–9.5) | 8.0 (7.1–9.2) | 0.33 |
| Hypertension, n (%) | 126 (63.0) | 61 (61.0) | 65 (65.0) | 0.56 |
| Current smoking, n (%) | 34 (17.0) | 18 (18.0) | 16 (16.0) | 0.71 |
4.3. Có nên đưa p-value vào Table 1 không?
Trong nghiên cứu quan sát, p-value trong Table 1 có thể giúp mô tả khác biệt giữa nhóm.
Trong RCT, nhiều hướng dẫn không khuyến khích quá chú trọng p-value ở baseline, vì khác biệt baseline là do ngẫu nhiên. Tuy vậy, nhiều tạp chí vẫn cho phép hoặc yêu cầu.
Thông điệp cho học viên:
Đừng dùng p-value ở Table 1 như cái máy phán “hai nhóm giống nhau hoàn toàn”. Hãy nhìn cả ý nghĩa lâm sàng. Chênh lệch tuổi 0,5 tuổi có thể p < 0,05 nếu mẫu cực lớn nhưng không quan trọng. Chênh lệch HbA1c 1,2% có thể không có ý nghĩa thống kê nếu mẫu nhỏ nhưng rất quan trọng lâm sàng.
4.4. Prompt AI tạo Table 1
Tạo code SPSS/Python để làm Table 1 so sánh đặc điểm nền giữa 2 nhóm Treatment A và Treatment B.
Dataset gồm các biến:
- Group: Treatment A hoặc Treatment B
- Continuous: Age, BMI, HbA1c, Duration_DM
- Categorical: Gender, Hypertension, Smoking
Yêu cầu:
1. Kiểm tra phân phối của biến định lượng
2. Nếu phân phối gần chuẩn: báo cáo mean ± SD
3. Nếu phân phối lệch: báo cáo median (IQR)
4. Biến định tính: báo cáo n (%)
5. Chọn test phù hợp:
- t-test hoặc Mann-Whitney cho biến định lượng
- Chi-square hoặc Fisher's exact cho biến định tính
6. Xuất bảng có các cột:
Variable, Total, Treatment A, Treatment B, p-value
7. Format bảng sẵn sàng đưa vào báo cáo
8. Giải thích ngắn gọn cách chọn test
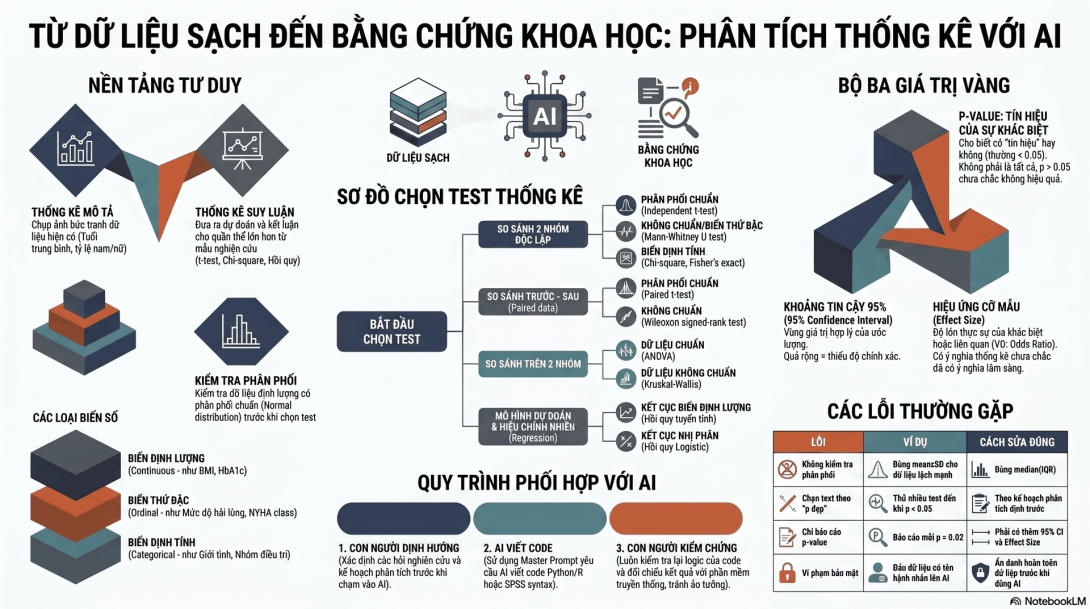
PHẦN 5: CHỌN TEST THỐNG KÊ PHÙ HỢP
5.1. Sơ đồ chọn test đơn giản
Bạn muốn phân tích gì?
│
├── Mô tả một nhóm
│ ├── Biến định lượng → mean±SD hoặc median(IQR)
│ └── Biến định tính → n (%)
│
├── So sánh 2 nhóm
│ ├── Biến định lượng, độc lập → t-test hoặc Mann-Whitney
│ ├── Biến định lượng, paired → paired t-test hoặc Wilcoxon signed-rank
│ └── Biến định tính → Chi-square hoặc Fisher's exact
│
├── So sánh >2 nhóm
│ ├── Biến định lượng → ANOVA hoặc Kruskal-Wallis
│ └── Biến định tính → Chi-square
│
├── Tương quan 2 biến định lượng
│ ├── Gần chuẩn/quan hệ tuyến tính → Pearson
│ └── Lệch/ordinal/không tuyến tính → Spearman
│
└── Dự đoán/hiệu chỉnh yếu tố nhiễu
├── Outcome liên tục → Linear regression
└── Outcome nhị phân → Logistic regression
5.2. So sánh 2 nhóm với biến định lượng
Independent t-test
Dùng khi:
- Có 2 nhóm độc lập.
- Outcome là biến định lượng.
- Dữ liệu gần chuẩn.
- Phương sai hai nhóm tương đối đồng nhất.
Ví dụ:
So sánh tuổi trung bình giữa nhóm Treatment A và Treatment B.
Mann-Whitney U test
Dùng khi:
- Có 2 nhóm độc lập.
- Outcome là biến định lượng hoặc thứ bậc.
- Dữ liệu lệch nhiều hoặc có outlier mạnh.
Ví dụ:
So sánh thời gian nằm viện giữa nhóm có biến chứng và không biến chứng.
5.3. So sánh trước–sau trong cùng một nhóm
Paired t-test
Dùng khi:
- Cùng một người được đo trước và sau.
- Biến định lượng.
- Hiệu số trước–sau gần chuẩn.
Ví dụ:
So sánh HbA1c trước và sau 12 tuần điều trị trong cùng bệnh nhân.
Wilcoxon signed-rank test
Dùng khi:
- Dữ liệu paired.
- Hiệu số trước–sau lệch nhiều.
Ví dụ:
So sánh điểm đau trước và sau can thiệp khi phân phối điểm đau lệch.
5.4. So sánh nhiều hơn 2 nhóm
ANOVA
Dùng khi:
- Có từ 3 nhóm độc lập trở lên.
- Outcome định lượng.
- Phân phối gần chuẩn.
- Phương sai tương đối đồng nhất.
Ví dụ:
So sánh HbA1c trung bình giữa 3 nhóm BMI: bình thường, thừa cân, béo phì.
Kruskal-Wallis
Dùng khi:
- Có từ 3 nhóm trở lên.
- Outcome định lượng nhưng lệch hoặc ordinal.
5.5. So sánh biến định tính
Chi-square test
Dùng khi:
- So sánh tỷ lệ giữa các nhóm.
- Expected cell count đủ lớn.
Ví dụ:
So sánh tỷ lệ đạt HbA1c < 7% giữa Treatment A và Treatment B.
Fisher’s exact test
Dùng khi:
- Bảng 2x2.
- Có ô có tần số kỳ vọng nhỏ.
Ví dụ:
So sánh tỷ lệ biến cố hiếm giữa hai nhóm nhỏ.
PHẦN 6: PHÂN TÍCH KẾT CỤC CHÍNH
Theo khung chương trình gốc, thực hành 2 của Bài 11 là so sánh kết cục chính: “Có khác biệt về mức giảm HbA1c giữa Treatment A và B sau 12 tuần không?”, với các bước kiểm tra giả định, chọn test, chạy phân tích và diễn giải kết quả.
6.1. Ví dụ câu hỏi nghiên cứu
Có khác biệt về mức giảm HbA1c giữa nhóm Treatment A và Treatment B sau 12 tuần không?
6.2. Biến cần có
| Biến | Ý nghĩa |
|---|---|
| Group | Treatment A hoặc Treatment B |
| HbA1c_baseline | HbA1c trước điều trị |
| HbA1c_12w | HbA1c sau 12 tuần |
| HbA1c_change | HbA1c_12w − HbA1c_baseline |
Thông thường, nếu HbA1c giảm, HbA1c_change sẽ là số âm. Có thể tạo biến “HbA1c reduction” theo hướng dương:
HbA1c_reduction = HbA1c_baseline - HbA1c_12w
Khi đó số càng lớn nghĩa là giảm càng nhiều, dễ diễn giải hơn.
6.3. Quy trình phân tích
Bước 1: Tạo biến HbA1c_reduction
Bước 2: Mô tả HbA1c_reduction theo từng nhóm
Bước 3: Kiểm tra phân phối HbA1c_reduction
Bước 4: Chọn test:
- Independent t-test nếu gần chuẩn
- Mann-Whitney nếu lệch nhiều
Bước 5: Báo cáo mean difference hoặc median difference
Bước 6: Báo cáo p-value, 95% CI và effect size nếu có
Bước 7: Diễn giải ý nghĩa thống kê và ý nghĩa lâm sàng
6.4. Prompt AI phân tích kết cục chính
Tôi có dữ liệu HbA1c trước và sau điều trị ở 2 nhóm.
Biến:
- Group: Treatment A hoặc Treatment B
- HbA1c_baseline
- HbA1c_12w
Câu hỏi nghiên cứu:
Có khác biệt về mức giảm HbA1c giữa Treatment A và Treatment B sau 12 tuần không?
Hãy:
1. Tạo biến HbA1c_reduction = HbA1c_baseline - HbA1c_12w
2. Mô tả HbA1c_reduction theo từng nhóm
3. Kiểm tra phân phối của HbA1c_reduction
4. Đề xuất test phù hợp
5. Viết code Python/SPSS để chạy phân tích
6. Tính effect size nếu phù hợp
7. Diễn giải kết quả theo phong cách báo cáo y khoa
8. Gợi ý cách trình bày trong phần Results
6.5. Cách diễn giải kết quả
Ví dụ 1: Có ý nghĩa thống kê và có ý nghĩa lâm sàng
Sau 12 tuần, mức giảm HbA1c trung bình ở nhóm Treatment A là 1,2 ± 0,8%, cao hơn so với nhóm Treatment B là 0,6 ± 0,7%. Khác biệt trung bình giữa hai nhóm là 0,6% với khoảng tin cậy 95% từ 0,2 đến 1,0; p = 0,004. Kết quả này cho thấy Treatment A có hiệu quả cải thiện HbA1c tốt hơn Treatment B sau 12 tuần.
Ví dụ 2: Có ý nghĩa thống kê nhưng ý nghĩa lâm sàng nhỏ
Mức giảm HbA1c ở nhóm Treatment A cao hơn nhóm Treatment B 0,15%, p = 0,03. Tuy nhiên, mức khác biệt này nhỏ và cần cân nhắc thêm về ý nghĩa lâm sàng.
Ví dụ 3: Không có ý nghĩa thống kê
Không ghi: “Treatment A không có hiệu quả.”
Nên ghi:
Nghiên cứu không ghi nhận sự khác biệt có ý nghĩa thống kê về mức giảm HbA1c giữa Treatment A và Treatment B sau 12 tuần. Cần cân nhắc cỡ mẫu, độ dao động dữ liệu và khoảng tin cậy khi diễn giải kết quả.
PHẦN 7: P-VALUE, KHOẢNG TIN CẬY VÀ EFFECT SIZE
7.1. p-value là gì?
p-value trả lời câu hỏi:
Nếu giả thuyết không đúng là “không có khác biệt”, thì xác suất quan sát được dữ liệu như hiện tại hoặc cực đoan hơn là bao nhiêu?
Nói đơn giản hơn:
- p nhỏ: dữ liệu ít phù hợp với giả thuyết không.
- p < 0,05 thường được xem là có ý nghĩa thống kê.
- Nhưng p-value không nói hiệu quả lớn hay nhỏ.
- p-value không nói kết quả có quan trọng lâm sàng hay không.
7.2. Những hiểu lầm thường gặp về p-value
| Hiểu lầm | Sửa lại |
|---|---|
| p < 0,05 nghĩa là chắc chắn đúng | Không, chỉ là bằng chứng thống kê |
| p > 0,05 nghĩa là không có hiệu quả | Không, có thể thiếu power |
| p càng nhỏ thì hiệu quả càng lớn | Không nhất thiết |
| p-value là kết quả quan trọng nhất | Không, cần xem effect size và 95% CI |
Câu thần chú:
p-value cho biết “có tín hiệu không”; effect size cho biết “tín hiệu lớn cỡ nào”; confidence interval cho biết “ước lượng chắc đến đâu”.
7.3. Khoảng tin cậy 95%
Khoảng tin cậy 95% cho biết vùng giá trị hợp lý của ước lượng.
Ví dụ:
Mean difference = 0,6%, 95% CI: 0,2 đến 1,0.
Diễn giải:
Dữ liệu gợi ý Treatment A giảm HbA1c nhiều hơn Treatment B khoảng 0,6%, và giá trị thật có thể nằm trong khoảng 0,2 đến 1,0%.
Nếu khoảng tin cậy rất rộng, kết quả thiếu chính xác.
7.4. Effect size
Effect size cho biết độ lớn của khác biệt hoặc liên quan.
Ví dụ:
| Loại phân tích | Effect size thường gặp |
|---|---|
| So sánh trung bình | Mean difference, Cohen’s d |
| So sánh tỷ lệ | Risk difference, risk ratio |
| Hồi quy logistic | Odds ratio |
| Tương quan | Correlation coefficient r |
| Hồi quy tuyến tính | Beta coefficient |
Trong y khoa, effect size quan trọng vì một khác biệt rất nhỏ nhưng p < 0,05 có thể không đáng thay đổi thực hành.
PHẦN 8: PHÂN TÍCH TƯƠNG QUAN
8.1. Khi nào dùng tương quan?
Dùng khi muốn đánh giá mối liên quan giữa hai biến định lượng.
Ví dụ:
- BMI và HbA1c.
- Tuổi và huyết áp tâm thu.
- Thời gian mắc đái tháo đường và HbA1c.
- Điểm stress và số giờ làm việc mỗi tuần.
8.2. Pearson hay Spearman?
| Test | Khi dùng |
|---|---|
| Pearson correlation | Hai biến định lượng, quan hệ tuyến tính, phân phối tương đối chuẩn |
| Spearman correlation | Dữ liệu lệch, có outlier, biến thứ bậc, hoặc quan hệ đơn điệu nhưng không tuyến tính |
8.3. Diễn giải hệ số tương quan
Hệ số tương quan r nằm từ -1 đến +1.
| r | Diễn giải gần đúng |
|---|---|
| 0 | Không tương quan tuyến tính |
| ±0,1 đến ±0,3 | Yếu |
| ±0,3 đến ±0,5 | Trung bình |
| > ±0,5 | Mạnh |
Ví dụ diễn giải
BMI có tương quan dương mức trung bình với HbA1c, r = 0,34, p = 0,01. Điều này cho thấy BMI cao hơn có xu hướng đi kèm HbA1c cao hơn, tuy nhiên kết quả này không chứng minh quan hệ nhân quả.
8.4. Prompt AI phân tích tương quan
Tôi muốn phân tích tương quan giữa BMI và HbA1c trong dataset bệnh nhân đái tháo đường.
Hãy:
1. Kiểm tra phân phối BMI và HbA1c
2. Vẽ scatter plot
3. Kiểm tra quan hệ tuyến tính
4. Đề xuất Pearson hay Spearman
5. Viết code Python/SPSS để chạy phân tích
6. Diễn giải hệ số tương quan, p-value và ý nghĩa lâm sàng
7. Nhắc rõ rằng tương quan không chứng minh nhân quả
PHẦN 9: HỒI QUY TUYẾN TÍNH VÀ HỒI QUY LOGISTIC
9.1. Vì sao cần hồi quy?
So sánh đơn giản thường chưa đủ vì trong y khoa có nhiều yếu tố nhiễu.
Ví dụ:
Treatment A có vẻ tốt hơn Treatment B, nhưng nhóm A có thể trẻ hơn, BMI thấp hơn, thời gian mắc bệnh ngắn hơn. Hồi quy giúp hiệu chỉnh nhiều yếu tố cùng lúc.
9.2. Hồi quy tuyến tính — Linear Regression
Dùng khi outcome là biến định lượng.
Ví dụ outcome:
- HbA1c sau 12 tuần.
- Mức giảm HbA1c.
- Huyết áp tâm thu.
- Điểm chất lượng sống.
- Thời gian nằm viện, nếu phân phối phù hợp hoặc đã biến đổi.
Ví dụ câu hỏi
Sau khi hiệu chỉnh tuổi, giới, BMI và thời gian mắc bệnh, Treatment A có liên quan đến mức giảm HbA1c nhiều hơn không?
Diễn giải beta
Nếu beta của Treatment A = 0,5:
Sau khi hiệu chỉnh các yếu tố khác, nhóm Treatment A có mức giảm HbA1c trung bình cao hơn nhóm Treatment B 0,5%.
9.3. Hồi quy logistic — Logistic Regression
Theo khung chương trình gốc, thực hành 3 của Bài 11 là hồi quy logistic với outcome “đạt target HbA1c < 7%”, predictors gồm tuổi, BMI, thời gian mắc đái tháo đường và nhóm điều trị.
Dùng khi outcome là biến nhị phân:
- Đạt HbA1c < 7%: có/không.
- Tử vong: có/không.
- Tái nhập viện: có/không.
- Biến chứng: có/không.
- Tuân thủ thuốc tốt: có/không.
Ví dụ mô hình
Outcome:
HbA1c_target = 1 nếu HbA1c < 7%
HbA1c_target = 0 nếu HbA1c ≥ 7%
Predictors:
- Age.
- BMI.
- Duration_DM.
- Treatment group.
Diễn giải odds ratio
Ví dụ:
OR = 1,80; 95% CI: 1,10–2,95; p = 0,02.
Diễn giải:
Sau khi hiệu chỉnh tuổi, BMI và thời gian mắc đái tháo đường, bệnh nhân ở nhóm Treatment A có odds đạt HbA1c < 7% cao hơn 1,8 lần so với nhóm Treatment B.
Cẩn thận
Không nên diễn giải OR là “nguy cơ cao hơn 1,8 lần” nếu outcome không hiếm. Với outcome phổ biến, OR có thể phóng đại so với risk ratio.
9.4. Prompt AI cho hồi quy logistic
Tôi muốn chạy hồi quy logistic cho nghiên cứu đái tháo đường.
Outcome:
- HbA1c_target: 1 nếu HbA1c < 7%, 0 nếu HbA1c ≥ 7%
Predictors:
- Treatment group: A/B
- Age
- BMI
- Duration_DM
- Gender
- Baseline_HbA1c
Hãy:
1. Viết code Python/SPSS để chạy univariate logistic regression
2. Viết code cho multivariable logistic regression
3. Xuất OR, 95% CI và p-value
4. Kiểm tra multicollinearity nếu có thể
5. Giải thích kết quả bằng tiếng Việt học thuật
6. Gợi ý cách trình bày bảng kết quả hồi quy
7. Cảnh báo các lỗi diễn giải thường gặp
PHẦN 10: AI TRONG PHÂN TÍCH THỐNG KÊ
Khung chương trình gốc nhấn mạnh AI có thể chuyển yêu cầu ngôn ngữ tự nhiên thành code, tự động kiểm tra giả định và hỗ trợ diễn giải kết quả.
10.1. AI có thể giúp gì?
AI có thể hỗ trợ:
- Viết code Python/R/SPSS syntax.
- Gợi ý test thống kê phù hợp.
- Tạo bảng mô tả.
- Kiểm tra phân phối.
- Vẽ biểu đồ.
- Tính effect size.
- Diễn giải kết quả.
- Tạo đoạn Results.
- Tìm lỗi trong code.
- Giải thích output SPSS.
10.2. AI không được làm gì thay bạn?
AI không được:
- Quyết định analysis plan sau khi đã nhìn kết quả.
- Tự chọn biến để “ra p đẹp”.
- Tự loại outlier không có lý do.
- Tự sửa dữ liệu.
- Tự kết luận hiệu quả lâm sàng.
- Tự tạo dữ liệu thiếu.
- Tự bịa số liệu, bảng hoặc kết quả.
- Tự viết kết luận vượt quá dữ liệu.
10.3. Nguyên tắc “AI viết code, con người hiểu code”
Dùng AI phân tích thống kê không có nghĩa là khỏi học thống kê.
Quy trình an toàn:
Câu hỏi nghiên cứu
↓
Analysis plan định trước
↓
AI gợi ý code/test
↓
Người nghiên cứu kiểm tra logic
↓
Chạy phân tích
↓
Kiểm tra output
↓
Diễn giải thận trọng
↓
Nhờ mentor/thống kê viên review nếu cần
Không dùng:
Dán data vào AI
↓
AI trả kết quả
↓
Copy vào báo cáo
↓
Hy vọng reviewer không hỏi
Đây là con đường rất nhanh, nhưng nhanh kiểu trượt cầu thang.
PHẦN 11: CÔNG CỤ SỬ DỤNG TRONG BÀI
11.1. SPSS
SPSS vẫn phổ biến trong các bệnh viện và trường y tại Việt Nam.
Ưu điểm:
- Giao diện dễ dùng.
- Nhiều người quen.
- Phù hợp phân tích cơ bản.
- Dễ xuất bảng.
Hạn chế:
- Khó tự động hóa nếu không dùng syntax.
- Một số phân tích nâng cao hạn chế.
- Bảng xuất ra thường cần chỉnh lại trước khi đưa vào bài báo.
11.2. ChatGPT/Claude
Dùng để:
- Viết code.
- Giải thích test.
- Tạo analysis plan.
- Diễn giải output.
- Tạo bảng kết quả.
- Dịch kết quả sang tiếng Anh học thuật.
Lưu ý:
Không nên dán dữ liệu bệnh nhân có định danh vào AI công cộng. Bài 2 đã nhấn mạnh rủi ro bảo mật, hallucination và trách nhiệm kiểm chứng khi dùng AI trong nghiên cứu.
11.3. Julius AI
Theo khung chương trình, Julius AI là công cụ chuyên cho data analysis, cho phép đặt câu hỏi bằng ngôn ngữ tự nhiên và có thể có gói miễn phí tùy thời điểm triển khai.
Dùng cho:
- Upload dataset.
- Hỏi bằng tiếng Anh tự nhiên.
- Tạo bảng.
- Vẽ biểu đồ.
- Phân tích nhanh.
Lưu ý:
Trước khi dùng với dữ liệu thật, cần kiểm tra chính sách bảo mật và không upload dữ liệu định danh bệnh nhân.
PHẦN 12: VIẾT KẾT QUẢ THỐNG KÊ CHO BÀI BÁO
12.1. Nguyên tắc viết Results
Phần Results cần:
- Trình bày khách quan.
- Không diễn giải quá mức.
- Không bàn luận nguyên nhân sâu.
- Không lặp lại toàn bộ bảng.
- Báo cáo số liệu chính kèm p-value, 95% CI nếu phù hợp.
- Dùng đúng thì quá khứ cho kết quả nghiên cứu.
12.2. Mẫu câu mô tả đặc điểm mẫu
A total of 200 patients were included in the analysis. The mean age was 58.4 ± 10.2 years, and 108 patients (54.0%) were female. The median baseline HbA1c was 8.1% (IQR, 7.2–9.4).
Bản tiếng Việt:
Tổng cộng 200 bệnh nhân được đưa vào phân tích. Tuổi trung bình là 58,4 ± 10,2 tuổi, và 108 bệnh nhân (54,0%) là nữ. HbA1c nền trung vị là 8,1% (IQR: 7,2–9,4).
12.3. Mẫu câu so sánh hai nhóm
The mean HbA1c reduction was greater in the Treatment A group than in the Treatment B group (1.2 ± 0.8% vs. 0.6 ± 0.7%; mean difference, 0.6%; 95% CI, 0.2–1.0; p = 0.004).
Bản tiếng Việt:
Mức giảm HbA1c trung bình ở nhóm Treatment A cao hơn nhóm Treatment B (1,2 ± 0,8% so với 0,6 ± 0,7%; khác biệt trung bình 0,6%; KTC 95%: 0,2–1,0; p = 0,004).
12.4. Mẫu câu hồi quy logistic
In the multivariable logistic regression model, Treatment A was independently associated with achieving HbA1c <7% after adjustment for age, BMI, diabetes duration, and baseline HbA1c (adjusted OR, 1.80; 95% CI, 1.10–2.95; p = 0.02).
Bản tiếng Việt:
Trong mô hình hồi quy logistic đa biến, Treatment A liên quan độc lập với khả năng đạt HbA1c <7% sau khi hiệu chỉnh tuổi, BMI, thời gian mắc đái tháo đường và HbA1c nền (OR hiệu chỉnh = 1,80; KTC 95%: 1,10–2,95; p = 0,02).
PHẦN 13: THỰC HÀNH TRÊN LỚP
Tổng thời lượng thực hành: 70 phút
Dataset sử dụng: diabetes dataset đã làm sạch từ Bài 10, đúng theo khung chương trình gốc.
Thực hành 1: Tạo Table 1 — 25 phút
Mục tiêu
Tạo bảng đặc điểm nền giữa 2 nhóm Treatment A và Treatment B.
Biến sử dụng
Biến định lượng:
- Age.
- BMI.
- HbA1c.
- Duration_DM.
Biến định tính:
- Gender.
- Hypertension.
- Smoking.
Nhiệm vụ
- Kiểm tra phân phối biến định lượng.
- Chọn mean ± SD hoặc median, IQR.
- Tính n (%) cho biến định tính.
- Chọn test phù hợp.
- Tạo bảng Table 1.
- Viết 3–4 câu mô tả kết quả chính.
Prompt dùng trên lớp
Tôi có dataset đã làm sạch từ nghiên cứu đái tháo đường.
Biến nhóm:
- Group: Treatment A hoặc Treatment B
Biến định lượng:
- Age
- BMI
- HbA1c
- Duration_DM
Biến định tính:
- Gender
- Hypertension
- Smoking
Hãy viết code Python để tạo Table 1:
1. Kiểm tra phân phối biến định lượng
2. Báo cáo mean±SD nếu gần chuẩn, median(IQR) nếu lệch
3. Báo cáo n (%) cho biến định tính
4. Chọn test phù hợp cho so sánh giữa 2 nhóm
5. Xuất bảng cuối cùng ra Excel
6. Ghi chú test nào được dùng cho từng biến
Thực hành 2: So sánh kết cục chính HbA1c — 20 phút
Câu hỏi nghiên cứu
Có khác biệt về mức giảm HbA1c giữa Treatment A và Treatment B sau 12 tuần không?
Biến sử dụng
- Group.
- HbA1c_baseline.
- HbA1c_12w.
- HbA1c_reduction.
Nhiệm vụ
- Tạo biến HbA1c_reduction.
- Mô tả HbA1c_reduction theo nhóm.
- Kiểm tra phân phối.
- Chọn test.
- Chạy phân tích.
- Diễn giải p-value, 95% CI, effect size.
- Viết đoạn Results ngắn.
Mẫu đoạn Results học viên cần tạo
Sau 12 tuần, mức giảm HbA1c trung bình ở nhóm Treatment A là ...%, so với ...% ở nhóm Treatment B. Khác biệt trung bình giữa hai nhóm là ...% với KTC 95% ..., p = .... Kết quả này cho thấy ...
Thực hành 3: Hồi quy logistic — 20 phút
Câu hỏi
Treatment A có làm tăng khả năng đạt HbA1c < 7% sau 12 tuần không, sau khi hiệu chỉnh tuổi, BMI và thời gian mắc đái tháo đường?
Outcome
HbA1c_target = 1 nếu HbA1c_12w < 7%
HbA1c_target = 0 nếu HbA1c_12w ≥ 7%
Predictors
- Group.
- Age.
- BMI.
- Duration_DM.
- Baseline_HbA1c.
Nhiệm vụ
- Tạo biến HbA1c_target.
- Chạy univariate logistic regression.
- Chạy multivariable logistic regression.
- Xuất OR, 95% CI, p-value.
- Viết kết quả theo phong cách bài báo.
Thực hành 4: AI kiểm tra lỗi diễn giải — 5 phút
Học viên dán đoạn Results của mình vào AI và dùng prompt:
Hãy đóng vai trò reviewer thống kê.
Đánh giá đoạn diễn giải kết quả sau:
[Dán đoạn Results]
Hãy kiểm tra:
1. Có diễn giải quá mức không?
2. Có nhầm p-value với ý nghĩa lâm sàng không?
3. Có báo cáo thiếu 95% CI hoặc effect size không?
4. Có dùng từ “chứng minh” sai chỗ không?
5. Đề xuất phiên bản viết lại tốt hơn.
PHẦN 14: CASE STUDY THẢO LUẬN
Case 1: Chọn sai test
Một học viên so sánh thời gian nằm viện giữa hai nhóm bằng t-test. Dữ liệu có median 6 ngày, IQR 4–12, nhiều bệnh nhân nằm viện >30 ngày.
Câu hỏi
- T-test có phù hợp không?
- Cần kiểm tra gì trước?
- Test nào có thể phù hợp hơn?
Gợi ý trả lời
Dữ liệu thời gian nằm viện thường lệch phải. Cần xem histogram, Q-Q plot và outlier. Nếu lệch nhiều, Mann-Whitney có thể phù hợp hơn. Có thể cân nhắc biến đổi log hoặc mô hình phù hợp hơn nếu phân tích nâng cao.
Case 2: p = 0,06 thì kết luận thế nào?
Một nghiên cứu có kết quả:
Mean difference = 0,5%, 95% CI: -0,02 đến 1,02; p = 0,06.
Nhóm nghiên cứu viết:
“Can thiệp không có hiệu quả.”
Câu hỏi
- Câu này có đúng không?
- Nên viết lại thế nào?
- Cần xem thêm gì?
Gợi ý trả lời
Không nên kết luận “không có hiệu quả”. Nên viết:
Nghiên cứu chưa ghi nhận khác biệt có ý nghĩa thống kê ở ngưỡng 0,05, mặc dù ước lượng hiệu quả cho thấy xu hướng giảm HbA1c nhiều hơn ở nhóm can thiệp. Cần nghiên cứu có cỡ mẫu lớn hơn để đánh giá chính xác hơn.
Cần xem cỡ mẫu, power, khoảng tin cậy và ý nghĩa lâm sàng.
Case 3: AI diễn giải quá đà
AI viết:
“Treatment A significantly improves diabetes control and should be adopted in all hospitals.”
Dữ liệu thực tế chỉ từ một nghiên cứu nhỏ, một bệnh viện, 80 bệnh nhân, theo dõi 12 tuần.
Câu hỏi
- AI diễn giải sai ở đâu?
- Nên viết lại thế nào?
- Bài học là gì?
Gợi ý trả lời
AI đã suy rộng quá mức. Nghiên cứu nhỏ một trung tâm không đủ để khuyến cáo áp dụng toàn quốc.
Viết lại:
Kết quả gợi ý Treatment A có thể cải thiện kiểm soát HbA1c trong bối cảnh nghiên cứu này. Cần các nghiên cứu lớn hơn, đa trung tâm và thời gian theo dõi dài hơn để xác nhận hiệu quả và tính khái quát.
PHẦN 15: LỖI THƯỜNG GẶP KHI PHÂN TÍCH THỐNG KÊ
| Lỗi | Ví dụ | Cách sửa |
|---|---|---|
| Không kiểm tra loại biến | Dùng t-test cho biến định tính | Xác định loại biến trước |
| Không kiểm tra phân phối | Dùng mean±SD cho dữ liệu rất lệch | Dùng median(IQR) |
| Chọn test theo p đẹp | Thử nhiều test đến khi p < 0,05 | Theo analysis plan định trước |
| Quên paired data | Dữ liệu trước–sau nhưng dùng independent t-test | Dùng paired t-test/Wilcoxon |
| Chỉ báo p-value | p = 0,03 | Báo cáo thêm effect size, 95% CI |
| Diễn giải p > 0,05 là không có hiệu quả | “Không hiệu quả” | “Chưa ghi nhận khác biệt có ý nghĩa thống kê” |
| Nhầm OR với RR | OR = 2 thành “nguy cơ gấp 2” | Diễn giải là odds, cẩn thận nếu outcome phổ biến |
| Không kiểm soát nhiễu | So sánh thô rồi kết luận nhân quả | Dùng hồi quy/thiết kế phù hợp |
| Upload dữ liệu định danh lên AI | Dán file bệnh nhân có tên, mã hồ sơ | Ẩn danh hoặc dùng dữ liệu giả lập |
| Không hiểu code AI viết | Chạy được nhưng không biết làm gì | Yêu cầu AI giải thích từng dòng |
PHẦN 16: CHECKLIST PHÂN TÍCH THỐNG KÊ
16.1. Checklist trước khi phân tích
- Dữ liệu đã được làm sạch.
- Có file raw data lưu riêng.
- Có cleaning log.
- Biến outcome chính đã được xác định.
- Analysis plan đã được viết trước.
- Đã xác định loại biến.
- Đã kiểm tra missing data.
- Đã kiểm tra outliers.
- Đã mã hóa biến rõ ràng.
- Không còn thông tin định danh trong file dùng với AI.
16.2. Checklist khi chọn test
- Outcome là định lượng hay định tính?
- Có mấy nhóm?
- Các nhóm độc lập hay paired?
- Biến định lượng có phân phối gần chuẩn không?
- Có outlier mạnh không?
- Cỡ mẫu mỗi nhóm có đủ không?
- Test đã chọn có phù hợp với mục tiêu không?
16.3. Checklist khi báo cáo kết quả
- Có n của từng nhóm.
- Có mean±SD hoặc median(IQR).
- Có n (%) cho biến định tính.
- Có p-value chính xác.
- Có 95% CI nếu phù hợp.
- Có effect size nếu phù hợp.
- Không kết luận vượt quá dữ liệu.
- Không dùng từ “chứng minh” khi chỉ có nghiên cứu quan sát.
- Có ghi rõ phần mềm/phương pháp phân tích.
PHẦN 17: PROMPT THƯ VIỆN CHO BÀI 11
Prompt 1: Chọn test thống kê
Tôi có câu hỏi nghiên cứu:
[Dán câu hỏi]
Thông tin dữ liệu:
- Outcome:
- Loại outcome: định lượng/nhị phân/thứ bậc
- Biến nhóm/phơi nhiễm:
- Số nhóm:
- Nhóm độc lập hay paired:
- Cỡ mẫu mỗi nhóm:
- Phân phối dữ liệu:
- Mục tiêu phân tích:
Hãy đề xuất test thống kê phù hợp.
Giải thích:
1. Vì sao chọn test đó
2. Giả định cần kiểm tra
3. Test thay thế nếu giả định không đạt
4. Cách báo cáo kết quả
Prompt 2: Giải thích output SPSS
Tôi chạy SPSS và có output sau:
[Dán output đã ẩn thông tin nhạy cảm]
Hãy giải thích:
1. Test nào đã được chạy
2. Kết quả chính là gì
3. p-value có ý nghĩa gì
4. Có cần báo cáo effect size hoặc 95% CI không
5. Viết đoạn Results bằng tiếng Việt học thuật
6. Cảnh báo nếu tôi đang diễn giải sai
Prompt 3: Viết Results từ bảng phân tích
Dưới đây là bảng kết quả phân tích:
[Dán bảng]
Hãy viết phần Results cho manuscript.
Yêu cầu:
- Không bàn luận nguyên nhân
- Không kết luận quá mức
- Báo cáo n, %, mean/median, p-value, 95% CI nếu có
- Văn phong y khoa học thuật
- Có bản tiếng Việt và bản tiếng Anh
Prompt 4: Kiểm tra analysis plan
Hãy đóng vai trò chuyên gia thống kê y học.
Đánh giá analysis plan sau:
[Dán analysis plan]
Hãy kiểm tra:
1. Phân tích có bám sát mục tiêu nghiên cứu không?
2. Test thống kê có phù hợp với loại biến không?
3. Có thiếu kiểm tra giả định không?
4. Có cần hồi quy để hiệu chỉnh yếu tố nhiễu không?
5. Có nguy cơ p-hacking không?
6. Đề xuất chỉnh sửa cụ thể.
PHẦN 18: BÀI TẬP VỀ NHÀ
Bài tập chính: Phân tích dataset nghiên cứu của bạn
Học viên sử dụng dataset đã làm sạch từ Bài 10 hoặc dataset mẫu nếu chưa có dữ liệu thật.
Yêu cầu nộp
- Mô tả dataset:
- Số dòng.
- Số biến.
- Outcome chính.
- Biến nhóm/phơi nhiễm chính.
- Table 1:
- Đặc điểm nền.
- Có n từng nhóm.
- Có test và p-value nếu phù hợp.
- Phân tích outcome chính:
- Chọn test.
- Giải thích vì sao chọn test.
- Báo cáo kết quả.
- Một phân tích bổ sung:
- Tương quan hoặc hồi quy logistic/linear.
- Đoạn Results ngắn 300–500 từ.
- Reflection 150–200 từ:
- AI đã giúp gì?
- AI sai hoặc gợi ý chưa phù hợp ở đâu?
- Bạn đã kiểm tra lại như thế nào?
Mẫu bài nộp
Tên đề tài:
Hiệu quả của Treatment A so với Treatment B trong cải thiện HbA1c ở bệnh nhân đái tháo đường type 2.
Dataset:
- n = 200
- Group: Treatment A/B
- Outcome chính: HbA1c_reduction sau 12 tuần
Phân tích chính:
Mức giảm HbA1c được so sánh giữa hai nhóm. Phân phối HbA1c_reduction được kiểm tra bằng histogram, Q-Q plot và Shapiro-Wilk test. Do dữ liệu gần chuẩn, independent t-test được sử dụng. Effect size được báo cáo bằng mean difference và 95% CI.
Kết quả:
[Điền kết quả thực tế]
AI use:
ChatGPT được sử dụng để gợi ý code Python và kiểm tra cấu trúc đoạn Results. Toàn bộ kết quả được kiểm tra lại bằng SPSS.
PHẦN 19: RUBRIC CHẤM ĐIỂM
| Tiêu chí | Điểm |
|---|---|
| Dataset được mô tả rõ | 1 |
| Table 1 đầy đủ và đúng định dạng | 2 |
| Chọn test phù hợp với loại biến và phân phối | 2 |
| Phân tích outcome chính đúng | 1.5 |
| Có báo cáo effect size/95% CI khi phù hợp | 1 |
| Diễn giải kết quả chính xác, không quá mức | 1 |
| Reflection về sử dụng AI có trách nhiệm | 1 |
| Trình bày sạch, dễ đọc | 0.5 |
| Tổng | 10 |
PHẦN 20: THÔNG ĐIỆP KẾT THÚC
Bài 11 là bài giúp học viên bước từ “có dữ liệu” sang “có bằng chứng”.
Hãy nhớ 6 câu:
1. Test thống kê phải đi sau câu hỏi nghiên cứu, không đi sau mong muốn có p đẹp.
2. Trước khi so sánh, hãy mô tả dữ liệu thật kỹ.
3. p-value không phải vua; effect size và khoảng tin cậy mới là hai vị cố vấn khó tính nhưng đáng tin.
4. AI có thể viết code rất nhanh, nhưng bạn phải hiểu code đang làm gì.
5. Không có cleaning log, không có analysis plan, không có kiểm chứng — kết quả rất dễ thành “ảo thuật thống kê”.
6. Một phân tích tốt không làm dữ liệu nói điều mình muốn; nó giúp dữ liệu nói điều nó thật sự có thể nói.
Soạn giả: Jack Doan
Phiên bản: 1.0
- Đăng nhập để gửi ý kiến
