
🎯 MỤC TIÊU
Về kiến thức:
- Hiểu học sâu — Deep Learning — là gì và khác gì với Machine Learning truyền thống.
- Giải thích được vì sao Deep Learning đặc biệt mạnh trong xử lý hình ảnh y học.
- Mô tả được nguyên lý cơ bản của Convolutional Neural Network — CNN.
- Hiểu các thành phần chính của CNN: convolutional layer, pooling layer, activation, fully connected layer.
- Hiểu khái niệm transfer learning và vì sao nó quan trọng khi dữ liệu y khoa hạn chế.
- Mô tả được các mô hình phổ biến như VGG, ResNet, EfficientNet.
- Giải thích được các chỉ số đánh giá mô hình hình ảnh: AUROC, sensitivity, specificity, accuracy, F1-score, confusion matrix.
- Hiểu vai trò của Grad-CAM trong giải thích mô hình hình ảnh.
Về kỹ năng:
- Chuẩn bị được dataset hình ảnh y học cơ bản cho Deep Learning.
- Chạy được notebook Google Colab sử dụng mô hình pretrained để phân loại ảnh.
- Áp dụng được transfer learning cho bài toán phân loại X-quang ngực.
- Đánh giá được mô hình bằng confusion matrix, AUROC, sensitivity và specificity.
- Tạo được Grad-CAM heatmap để xem vùng ảnh mô hình chú ý.
- Dùng AI để hỗ trợ viết code, giải thích lỗi và diễn giải kết quả.
- Nhận diện được các lỗi nguy hiểm: data leakage, overfitting, bias, thiếu external validation.
Về thái độ:
- Không xem mô hình AI hình ảnh là “bác sĩ thay thế”.
- Không tin mô hình chỉ vì accuracy cao.
- Luôn kiểm tra dữ liệu, nhãn, quy trình chia train/test và khả năng khái quát.
- Có ý thức bảo mật hình ảnh y khoa và metadata.
- Tôn trọng vai trò cuối cùng của bác sĩ, kỹ thuật viên và hội đồng chuyên môn.
PHẦN 1: DEEP LEARNING LÀ GÌ?
1.1. Định nghĩa đơn giản
Deep Learning — Học sâu là một nhánh của Machine Learning sử dụng mạng nơ-ron nhiều lớp để học các đặc trưng phức tạp từ dữ liệu.
Trong hình ảnh y học, Deep Learning có thể học từ:
- X-quang.
- CT.
- MRI.
- Siêu âm.
- Nội soi.
- Hình mô bệnh học.
- Ảnh da liễu.
- Ảnh đáy mắt.
- Ảnh ECG dạng ảnh hoặc tín hiệu.
Ví dụ:
Cho mô hình xem hàng nghìn ảnh X-quang ngực đã được gắn nhãn “bình thường” hoặc “viêm phổi”. Sau khi học, mô hình có thể dự đoán xác suất một ảnh X-quang mới có dấu hiệu viêm phổi.
1.2. Deep Learning khác Machine Learning truyền thống thế nào?
| Tiêu chí | Machine Learning truyền thống | Deep Learning |
|---|---|---|
| Dữ liệu thường dùng | Bảng số liệu, biến lâm sàng | Hình ảnh, âm thanh, văn bản, tín hiệu |
| Feature engineering | Con người chọn đặc trưng | Mô hình tự học đặc trưng |
| Nhu cầu dữ liệu | Thấp–trung bình | Thường cao hơn |
| Diễn giải | Thường dễ hơn | Khó hơn |
| Tài nguyên tính toán | Ít hơn | Cần GPU nếu dữ liệu lớn |
| Ví dụ | Logistic regression, Random Forest | CNN, ResNet, EfficientNet |
Ví dụ dễ hiểu
Với Machine Learning truyền thống cho ảnh X-quang, con người phải định nghĩa đặc trưng:
- Vùng mờ.
- Kích thước tổn thương.
- Độ tương phản.
- Texture.
- Vị trí tổn thương.
Với Deep Learning, mô hình tự học các đặc trưng qua nhiều lớp xử lý ảnh. Nó có thể học từ cạnh, đường nét, vùng sáng/tối, texture, cho đến cấu trúc phức tạp hơn.
Ẩn dụ: Machine Learning truyền thống giống như bạn đưa cho máy một bảng checklist. Deep Learning giống như cho máy xem rất nhiều ảnh và để nó tự học cách nhận ra pattern. Nghe rất thông minh, nhưng nếu cho học nhầm ảnh, nó cũng thông minh theo hướng… hơi nguy hiểm.
PHẦN 2: VÌ SAO DEEP LEARNING MẠNH TRONG HÌNH ẢNH Y HỌC?
Khung chương trình gốc nhấn mạnh ba lý do: automatic feature extraction, hiệu năng cao trong tác vụ hình ảnh, và ứng dụng rộng trong X-quang, CT, MRI, pathology.
2.1. Hình ảnh chứa nhiều thông tin phức tạp
Một ảnh X-quang ngực có hàng trăm nghìn đến hàng triệu pixel. Mắt người có thể nhận ra pattern, nhưng rất khó chuyển toàn bộ pattern đó thành vài biến số trong bảng Excel.
Deep Learning phù hợp vì nó xử lý trực tiếp dữ liệu hình ảnh.
2.2. CNN học đặc trưng theo tầng
Các lớp đầu học đặc trưng đơn giản:
- Cạnh.
- Đường viền.
- Góc.
- Vùng sáng/tối.
Các lớp giữa học đặc trưng phức tạp hơn:
- Texture.
- Hình dạng.
- Vùng tổn thương.
Các lớp cuối học pattern liên quan đến nhãn:
- Bình thường.
- Viêm phổi.
- Tràn dịch màng phổi.
- Khối u.
- Bất thường mô bệnh học.
2.3. Ứng dụng trong y học
| Lĩnh vực | Ví dụ ứng dụng |
|---|---|
| X-quang ngực | Viêm phổi, lao phổi, tràn khí, tim to |
| CT | Xuất huyết não, nốt phổi, COVID-19, ung thư |
| MRI | U não, tổn thương khớp, đột quỵ |
| Mô bệnh học | Phân loại ung thư, grading, phát hiện vi di căn |
| Da liễu | Phân loại tổn thương da, melanoma |
| Nhãn khoa | Bệnh võng mạc đái tháo đường, glaucoma |
| Siêu âm | Gan nhiễm mỡ, tổn thương tuyến giáp, thai kỳ |
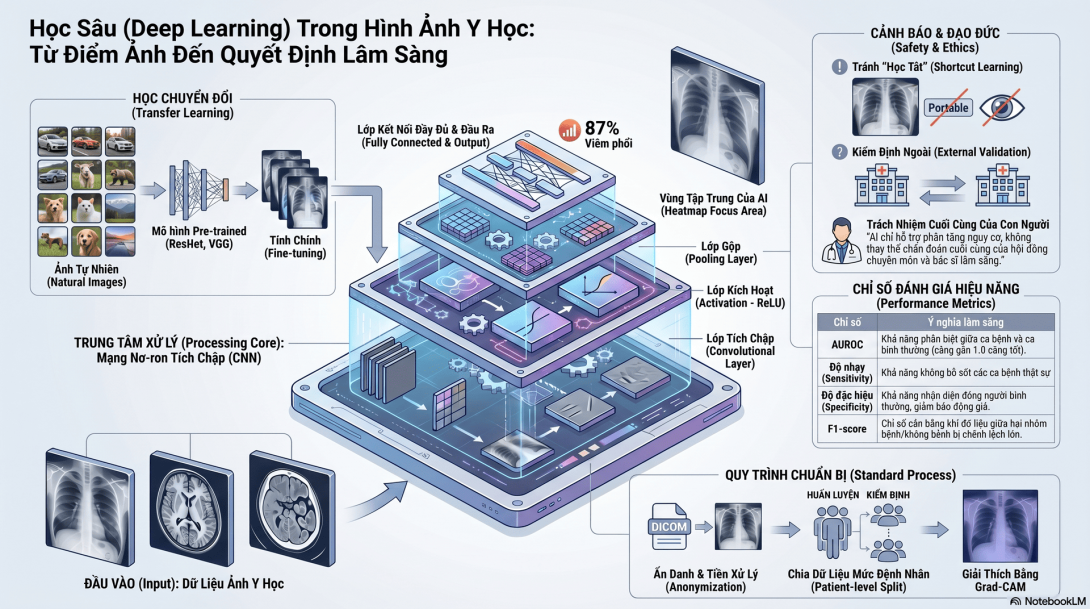
PHẦN 3: CNN — CONVOLUTIONAL NEURAL NETWORK
3.1. CNN là gì?
CNN là loại mạng nơ-ron được thiết kế đặc biệt cho dữ liệu dạng lưới, nhất là hình ảnh.
Một ảnh có thể xem như ma trận pixel:
Ảnh grayscale: cao × rộng
Ảnh màu: cao × rộng × 3 kênh màu
Ảnh X-quang: thường grayscale
CNN học bằng cách dùng các bộ lọc — filters/kernels — quét qua ảnh để phát hiện pattern.
3.2. Các thành phần chính của CNN
A. Convolutional layer
Lớp convolution dùng filter để phát hiện đặc trưng.
Ví dụ:
- Filter phát hiện cạnh ngang.
- Filter phát hiện cạnh dọc.
- Filter phát hiện vùng sáng bất thường.
- Filter phát hiện texture.
Input image → Convolution filters → Feature maps
B. Activation function
Sau convolution, mô hình dùng hàm kích hoạt, thường là ReLU.
ReLU(x) = max(0, x)
Mục đích là giúp mô hình học quan hệ phi tuyến. Không có activation, mạng sâu sẽ giống một phép biến đổi tuyến tính dài dòng, hơi giống làm 10 bước nhưng vẫn đứng yên tại chỗ.
C. Pooling layer
Pooling giúp giảm kích thước feature map và giữ thông tin quan trọng.
Ví dụ:
- Max pooling lấy giá trị lớn nhất trong một vùng nhỏ.
- Average pooling lấy trung bình.
Mục đích:
- Giảm số tham số.
- Giảm tính toán.
- Giúp mô hình bớt nhạy với dịch chuyển nhỏ.
D. Fully connected layer
Sau khi CNN trích xuất đặc trưng, fully connected layer dùng các đặc trưng đó để phân loại.
Ví dụ:
Feature maps → Flatten / Global Average Pooling → Dense layer → Probability
E. Output layer
Với bài toán phân loại nhị phân:
Normal vs Pneumonia
Output có thể là xác suất:
P(pneumonia) = 0.87
3.3. CNN học như thế nào?
Mô hình học bằng cách:
- Nhận ảnh đầu vào.
- Dự đoán nhãn.
- So sánh với nhãn thật.
- Tính loss.
- Điều chỉnh trọng số bằng backpropagation.
- Lặp lại qua nhiều epoch.
Image → Prediction → Loss → Weight update → Better prediction
PHẦN 4: TRANSFER LEARNING
Khung chương trình gốc nhấn mạnh transfer learning: dùng mô hình pretrained, fine-tuning cho ảnh y học, giúp giảm nhu cầu dữ liệu.
4.1. Transfer learning là gì?
Transfer learning là kỹ thuật dùng một mô hình đã được huấn luyện trước trên dataset lớn, sau đó điều chỉnh cho bài toán mới.
Ví dụ:
- ResNet50 đã học từ ImageNet.
- Ta dùng ResNet50 làm nền.
- Thay lớp cuối để phân loại X-quang: normal vs pneumonia.
- Fine-tune trên dataset X-quang.
4.2. Vì sao transfer learning quan trọng trong y khoa?
Dữ liệu y khoa thường:
- Khó thu thập.
- Cần chuyên gia gắn nhãn.
- Có vấn đề bảo mật.
- Ít hơn ảnh tự nhiên rất nhiều.
- Không cân bằng giữa nhóm bệnh và nhóm bình thường.
Transfer learning giúp:
- Cần ít dữ liệu hơn.
- Huấn luyện nhanh hơn.
- Hiệu năng ban đầu tốt hơn.
- Giảm chi phí tính toán.
4.3. Các chiến lược transfer learning
Cách 1: Feature extraction
Đóng băng toàn bộ pretrained model, chỉ huấn luyện lớp cuối.
Phù hợp khi:
- Dataset nhỏ.
- GPU hạn chế.
- Muốn demo nhanh.
- Sợ overfitting.
Cách 2: Fine-tuning một phần
Mở khóa một số lớp cuối của mô hình để huấn luyện lại.
Phù hợp khi:
- Dataset trung bình.
- Có GPU.
- Cần cải thiện hiệu năng.
- Đã kiểm soát overfitting.
Cách 3: Fine-tuning toàn bộ
Huấn luyện lại toàn mô hình.
Phù hợp khi:
- Dataset lớn.
- Có GPU tốt.
- Có chuyên môn ML.
- Có kế hoạch validation nghiêm túc.
PHẦN 5: CÁC MÔ HÌNH PHỔ BIẾN
5.1. VGG
VGG là kiến trúc CNN cổ điển, dễ hiểu.
Ưu điểm:
- Cấu trúc đơn giản.
- Dễ giải thích cho người mới.
- Dễ dùng để học nguyên lý.
Hạn chế:
- Nhiều tham số.
- Nặng.
- Không còn là lựa chọn tối ưu trong nhiều bài toán hiện đại.
5.2. ResNet
ResNet dùng residual connections, giúp huấn luyện mạng sâu hơn.
Ưu điểm:
- Mạnh.
- Phổ biến.
- Có nhiều biến thể: ResNet18, ResNet50, ResNet101.
- Thường dùng làm baseline tốt.
Hạn chế:
- Khó giải thích hơn VGG một chút.
- Vẫn cần tuning và validation tốt.
5.3. EfficientNet
EfficientNet được thiết kế để cân bằng độ sâu, độ rộng và độ phân giải ảnh.
Ưu điểm:
- Hiệu năng tốt.
- Tối ưu tài nguyên.
- Phù hợp khi muốn mô hình mạnh nhưng không quá nặng.
Hạn chế:
- Khó giải thích kiến trúc cho người mới.
- Cần cẩn thận khi áp dụng vào ảnh y học.
PHẦN 6: WORKFLOW DEEP LEARNING CHO HÌNH ẢNH Y HỌC
6.1. Quy trình tổng quát
1. Xác định câu hỏi lâm sàng
↓
2. Xác định outcome/label
↓
3. Thu thập và ẩn danh ảnh
↓
4. Kiểm tra chất lượng ảnh và nhãn
↓
5. Chia train/validation/test
↓
6. Tiền xử lý ảnh
↓
7. Chọn mô hình pretrained
↓
8. Huấn luyện / fine-tuning
↓
9. Đánh giá hiệu năng
↓
10. Tạo Grad-CAM / interpretability
↓
11. Kiểm tra bias, leakage, external validation
↓
12. Báo cáo theo TRIPOD+AI / CLAIM nếu phù hợp
6.2. Bước 1 — Xác định câu hỏi lâm sàng
Câu hỏi yếu:
AI đọc X-quang có tốt không?
Câu hỏi tốt hơn:
Mô hình CNN sử dụng ảnh X-quang ngực thẳng có thể phân loại bình thường và viêm phổi ở bệnh nhân người lớn với hiệu năng như thế nào?
Câu hỏi tốt hơn nữa:
Ở bệnh nhân người lớn chụp X-quang ngực tại khoa Cấp cứu, mô hình CNN sử dụng ảnh X-quang ngực thẳng có thể hỗ trợ phát hiện viêm phổi so với nhãn tham chiếu của bác sĩ chẩn đoán hình ảnh hay không?
6.3. Bước 2 — Xác định nhãn
Nhãn — label — là “sự thật tham chiếu” mà mô hình học.
Ví dụ:
0 = Normal
1 = Pneumonia
Ai gắn nhãn?
- Một bác sĩ chẩn đoán hình ảnh?
- Hai bác sĩ độc lập?
- Consensus giữa các bác sĩ?
- Dựa trên báo cáo X-quang?
- Dựa trên CT hoặc chẩn đoán cuối cùng?
- Dựa trên hồ sơ bệnh án?
Nhãn kém thì mô hình học kém. Nếu nhãn sai hàng loạt, mô hình có thể đạt accuracy cao bằng cách học sai một cách rất chăm chỉ.
6.4. Bước 3 — Ẩn danh hình ảnh
Ảnh y học có thể chứa:
- Tên bệnh nhân.
- Mã bệnh án.
- Ngày chụp.
- Tên bệnh viện.
- Metadata DICOM.
- Thông tin máy chụp.
- Thông tin vị trí hoặc đơn vị.
Cần:
- Xóa metadata định danh.
- Loại bỏ chữ in trên ảnh nếu có.
- Mã hóa ID.
- Lưu khóa mã hóa riêng.
- Tuân thủ phê duyệt đạo đức và chính sách bệnh viện.
6.5. Bước 4 — Chia dữ liệu đúng cách
Nguyên tắc cực kỳ quan trọng:
Không để ảnh của cùng một bệnh nhân xuất hiện ở cả train và test.
Nếu một bệnh nhân có nhiều ảnh, phải chia theo patient-level split, không phải image-level split.
Sai nguy hiểm
Ảnh 1 của bệnh nhân A → train
Ảnh 2 của bệnh nhân A → test
Mô hình có thể học đặc điểm riêng của bệnh nhân hoặc máy chụp, làm test performance đẹp giả tạo.
Đúng
Tất cả ảnh của bệnh nhân A → cùng một tập: train hoặc validation hoặc test
6.6. Bước 5 — Tiền xử lý ảnh
Các bước phổ biến:
- Resize ảnh, ví dụ 224 × 224.
- Normalize pixel values.
- Convert grayscale sang 3 channels nếu dùng pretrained ImageNet model.
- Data augmentation: xoay nhẹ, dịch chuyển nhẹ, zoom nhẹ.
- Không augmentation quá mức làm sai ý nghĩa y khoa.
Cẩn thận với augmentation
Có thể dùng:
- Rotate nhẹ.
- Shift nhẹ.
- Zoom nhẹ.
- Contrast adjustment nhẹ.
Cần tránh:
- Lật trái–phải nếu bên tổn thương quan trọng.
- Xoay quá nhiều khiến ảnh không giống thực tế.
- Crop mất vùng phổi.
- Tạo ảnh giả làm sai dấu hiệu bệnh.
PHẦN 7: ĐÁNH GIÁ MÔ HÌNH
Khung chương trình gốc yêu cầu đánh giá bằng AUROC, sensitivity, specificity, confusion matrix và Grad-CAM.
7.1. Confusion matrix
| Thực tế viêm phổi | Thực tế bình thường | |
|---|---|---|
| Dự đoán viêm phổi | True Positive | False Positive |
| Dự đoán bình thường | False Negative | True Negative |
7.2. Sensitivity
Sensitivity trả lời:
Trong số ca thật sự viêm phổi, mô hình phát hiện được bao nhiêu?
Quan trọng khi không muốn bỏ sót bệnh.
7.3. Specificity
Specificity trả lời:
Trong số ca thật sự không viêm phổi, mô hình nhận đúng bao nhiêu?
Quan trọng khi muốn giảm báo động giả.
7.4. AUROC
AUROC đo khả năng phân biệt giữa ca bệnh và không bệnh.
| AUROC | Diễn giải gần đúng |
|---|---|
| 0.5 | Không hơn đoán mò |
| 0.6–0.7 | Yếu |
| 0.7–0.8 | Chấp nhận được |
| 0.8–0.9 | Tốt |
| >0.9 | Rất tốt, nhưng cần kiểm tra leakage/overfitting |
7.5. F1-score
F1-score hữu ích khi dữ liệu mất cân bằng.
Ví dụ:
- 90% ảnh bình thường.
- 10% ảnh viêm phổi.
Nếu mô hình đoán tất cả là bình thường, accuracy = 90%, nhưng sensitivity với viêm phổi = 0. Mô hình này rất “giỏi” theo accuracy nhưng vô dụng trong lâm sàng. Accuracy đôi khi là cậu học trò điểm cao nhưng làm sai câu quan trọng nhất.
PHẦN 8: GRAD-CAM — GIẢI THÍCH MÔ HÌNH NHÌN Ở ĐÂU
8.1. Grad-CAM là gì?
Grad-CAM là kỹ thuật tạo heatmap cho thấy vùng ảnh mà mô hình chú ý khi đưa ra dự đoán.
Ví dụ:
- Mô hình dự đoán viêm phổi.
- Grad-CAM cho thấy mô hình tập trung vào vùng phổi phải có đám mờ.
- Điều này tăng niềm tin rằng mô hình đang nhìn vào vùng có ý nghĩa lâm sàng.
8.2. Grad-CAM giúp gì?
- Kiểm tra mô hình có nhìn đúng vùng tổn thương không.
- Phát hiện mô hình học sai shortcut.
- Hỗ trợ giải thích với bác sĩ.
- Tăng tính minh bạch.
- Hữu ích trong báo cáo nghiên cứu.
8.3. Grad-CAM có giới hạn gì?
Grad-CAM không chứng minh mô hình “hiểu” bệnh. Nó chỉ gợi ý vùng ảnh ảnh hưởng đến dự đoán.
Ví dụ nguy hiểm:
- Mô hình dự đoán viêm phổi nhưng Grad-CAM tập trung vào chữ “portable” trên ảnh.
- Mô hình dự đoán bệnh dựa vào marker của bệnh viện.
- Mô hình học rằng ảnh từ máy chụp ICU thường bệnh nặng hơn.
Khi đó model không học bệnh, mà học “dấu vết hệ thống”. Rất nhanh, rất tự tin, và rất dễ khiến mình tưởng là thông minh.
PHẦN 9: DATA LEAKAGE VÀ BIAS TRONG MEDICAL IMAGING
9.1. Data leakage trong hình ảnh
Các dạng leakage thường gặp:
| Leakage | Ví dụ |
|---|---|
| Patient leakage | Ảnh cùng bệnh nhân nằm ở cả train và test |
| Metadata leakage | File name chứa nhãn bệnh |
| Text marker leakage | Ảnh bệnh có chữ/máy chụp khác biệt |
| Preprocessing leakage | Normalize bằng toàn bộ dataset trước khi split |
| Duplicate leakage | Ảnh trùng hoặc gần trùng ở train/test |
| Hospital leakage | Train/test chia ngẫu nhiên ảnh, nhưng bệnh viện có pattern riêng |
9.2. Bias trong hình ảnh y học
Mô hình có thể kém trên:
- Bệnh viện khác.
- Máy chụp khác.
- Nhóm tuổi khác.
- Giới tính khác.
- Người có bệnh nền khác.
- Người Việt nếu model huấn luyện từ dữ liệu nước ngoài.
- Ảnh chất lượng thấp hơn.
- Ảnh từ tuyến huyện/tỉnh.
9.3. Cần kiểm tra subgroup
Nếu có dữ liệu, nên đánh giá hiệu năng theo:
- Tuổi.
- Giới.
- Bệnh viện.
- Loại máy chụp.
- Khoa phòng.
- Ngoại trú/nội trú/ICU.
- Chất lượng ảnh.
- Mức độ nặng.
PHẦN 10: CÔNG CỤ TRONG BÀI
Khung gốc đề xuất dùng Google Colab, TensorFlow/Keras và ChatGPT hỗ trợ code.
10.1. Google Colab
Dùng để:
- Chạy Python trên trình duyệt.
- Dùng GPU miễn phí hoặc trả phí.
- Chạy TensorFlow/Keras.
- Chia sẻ notebook.
- Thực hành Deep Learning mà không cần cài đặt phức tạp.
10.2. TensorFlow/Keras
Dùng để:
- Load pretrained model.
- Xây dựng CNN.
- Huấn luyện mô hình.
- Fine-tuning.
- Đánh giá mô hình.
- Tạo prediction.
10.3. ChatGPT/Claude
Dùng để:
- Viết code mẫu.
- Giải thích lỗi Python.
- Giải thích architecture.
- Tạo checklist.
- Viết đoạn Methods/Results.
- Giải thích output.
- Gợi ý cách trình bày Grad-CAM.
Không dùng để:
- Upload ảnh bệnh nhân có định danh.
- Tạo dữ liệu giả cho nghiên cứu thật.
- Tự kết luận mô hình đủ dùng lâm sàng.
- Bịa kết quả model.
- Bỏ qua kiểm tra chuyên gia.
PHẦN 11: PROJECT THỰC HÀNH — CHEST X-RAY CLASSIFICATION
11.1. Chủ đề thực hành
Phân loại ảnh X-quang ngực: bình thường vs viêm phổi.
Theo khung gốc, project dùng dataset X-quang ngực công khai như NIH Chest X-ray hoặc dataset tương tự, tác vụ là phân loại bình thường/viêm phổi; code structure gồm load ResNet50, thay lớp cuối, fine-tune, đánh giá test set và tạo Grad-CAM.
11.2. Dataset thực hành
Có thể dùng một trong ba lựa chọn:
Lựa chọn A: Dataset public đã chuẩn bị sẵn bởi giảng viên
Khuyến nghị cho lớp học vì tiết kiệm thời gian.
Cấu trúc thư mục:
data/
├── train/
│ ├── normal/
│ └── pneumonia/
├── val/
│ ├── normal/
│ └── pneumonia/
└── test/
├── normal/
└── pneumonia/
Lựa chọn B: Dataset công khai
Ví dụ:
- NIH Chest X-ray.
- RSNA Pneumonia Detection Challenge.
- Kaggle Chest X-ray Pneumonia dataset.
Lựa chọn C: Dataset bệnh viện đã ẩn danh
Chỉ dùng nếu:
- Có phê duyệt đạo đức.
- Đã ẩn danh đúng.
- Không còn metadata định danh.
- Có nhãn chất lượng.
- Có chính sách bảo mật rõ.
PHẦN 12: THỰC HÀNH TRÊN LỚP
Tổng thời lượng thực hành: 75 phút
Thực hành 1: Chuẩn bị môi trường Google Colab — 10 phút
Nhiệm vụ
- Mở Google Colab.
- Bật GPU:
- Runtime → Change runtime type → GPU.
- Import thư viện.
- Mount Google Drive nếu cần.
- Kiểm tra dataset.
Prompt AI hỗ trợ
Tôi đang dùng Google Colab để xây dựng mô hình phân loại X-quang ngực normal vs pneumonia.
Hãy viết code Python để:
1. Kiểm tra GPU
2. Import TensorFlow/Keras, numpy, pandas, matplotlib, sklearn
3. Kiểm tra cấu trúc thư mục dataset
4. Đếm số ảnh trong train/validation/test theo từng class
5. Hiển thị 6 ảnh mẫu từ mỗi class
Yêu cầu:
- Code có comment tiếng Việt
- Không sửa dữ liệu gốc
Thực hành 2: Data loading và preprocessing — 15 phút
Mục tiêu
Load ảnh và chuẩn bị cho model pretrained.
Các bước
- Resize ảnh về 224 × 224.
- Batch size: 16 hoặc 32.
- Normalize pixel values.
- Data augmentation nhẹ cho train set.
- Không augmentation cho validation/test.
Prompt AI hỗ trợ
Viết code TensorFlow/Keras để load dataset ảnh X-quang ngực từ thư mục:
data/
├── train/normal
├── train/pneumonia
├── val/normal
├── val/pneumonia
├── test/normal
└── test/pneumonia
Yêu cầu:
1. Resize ảnh về 224x224
2. Batch size = 32
3. Dùng image_dataset_from_directory
4. Tạo data augmentation nhẹ cho train set
5. Prefetch để tăng tốc
6. In class names và số batch
7. Có comment bằng tiếng Việt
Thực hành 3: Build model bằng transfer learning — 20 phút
Mục tiêu
Dùng ResNet50 pretrained, thay lớp cuối để phân loại nhị phân.
Code logic
# 1. Load pre-trained ResNet50 without top layer
# 2. Freeze base model
# 3. Add GlobalAveragePooling2D
# 4. Add Dropout
# 5. Add Dense(1, activation='sigmoid')
# 6. Compile model
# 7. Train
Prompt AI hỗ trợ
Viết code TensorFlow/Keras để xây dựng mô hình transfer learning cho phân loại X-quang ngực normal vs pneumonia.
Yêu cầu:
1. Dùng ResNet50 pretrained trên ImageNet, include_top=False
2. Input shape 224x224x3
3. Freeze toàn bộ base model ở giai đoạn đầu
4. Thêm GlobalAveragePooling2D
5. Thêm Dropout 0.3
6. Output Dense 1 neuron, sigmoid activation
7. Compile với Adam, binary_crossentropy
8. Metrics gồm accuracy, AUC, sensitivity, specificity nếu có thể
9. Train 5 epochs trên train set và validation set
10. Vẽ learning curves cho loss và AUC
11. Có comment bằng tiếng Việt
Thực hành 4: Fine-tuning — 10 phút
Mục tiêu
Mở khóa một số lớp cuối để cải thiện model.
Lưu ý
Fine-tuning cần learning rate thấp.
Ví dụ:
learning_rate = 1e-5
Prompt AI hỗ trợ
Tiếp tục từ mô hình ResNet50 đã huấn luyện feature extraction.
Hãy viết code fine-tuning:
1. Unfreeze 20 layers cuối của base model
2. Giữ BatchNormalization layers frozen nếu cần
3. Compile lại với learning rate thấp 1e-5
4. Train thêm 5 epochs
5. Vẽ lại learning curves
6. So sánh validation AUC trước và sau fine-tuning
Thực hành 5: Evaluation trên test set — 10 phút
Nhiệm vụ
- Tạo prediction probabilities.
- Chọn threshold 0.5.
- Tạo confusion matrix.
- Tính accuracy, sensitivity, specificity, PPV, NPV, F1-score.
- Vẽ ROC curve và tính AUROC.
Prompt AI hỗ trợ
Tôi đã có mô hình Keras phân loại normal vs pneumonia và test_dataset.
Hãy viết code để:
1. Tạo predicted probabilities cho test set
2. Lấy y_true và y_pred
3. Tính confusion matrix
4. Tính accuracy, sensitivity, specificity, PPV, NPV, F1-score
5. Vẽ ROC curve
6. Tính AUROC
7. In kết quả thành bảng
8. Diễn giải ngắn kết quả bằng tiếng Việt
Thực hành 6: Grad-CAM — 10 phút
Nhiệm vụ
- Chọn 3 ảnh dự đoán đúng.
- Chọn 3 ảnh dự đoán sai.
- Tạo Grad-CAM heatmap.
- Thảo luận mô hình nhìn đúng vùng phổi hay nhìn nhầm vùng khác.
Prompt AI hỗ trợ
Tôi có mô hình Keras dùng ResNet50 để phân loại ảnh X-quang ngực.
Hãy viết code tạo Grad-CAM:
1. Chọn layer convolution cuối cùng phù hợp
2. Tạo heatmap cho một ảnh đầu vào
3. Overlay heatmap lên ảnh gốc
4. Hiển thị predicted probability và true label
5. Tạo Grad-CAM cho 3 ảnh dự đoán đúng và 3 ảnh dự đoán sai
6. Có comment tiếng Việt
PHẦN 13: VIẾT KẾT QUẢ CHO BÁO CÁO
13.1. Mẫu Methods
We developed a convolutional neural network model to classify chest radiographs as normal or pneumonia. A pretrained ResNet50 model was used as the backbone, with the final classification layer replaced by a binary sigmoid output. Images were resized to 224 × 224 pixels and normalized prior to training. The dataset was split into training, validation, and test sets at the patient level where possible. Model performance was evaluated on the held-out test set using AUROC, sensitivity, specificity, positive predictive value, negative predictive value, and confusion matrix. Grad-CAM was used to visualize image regions contributing to model predictions.
Bản tiếng Việt:
Chúng tôi xây dựng mô hình mạng nơ-ron tích chập để phân loại ảnh X-quang ngực thành bình thường hoặc viêm phổi. Mô hình ResNet50 pretrained được sử dụng làm backbone, với lớp phân loại cuối được thay thế bằng đầu ra sigmoid nhị phân. Ảnh được resize về 224 × 224 pixel và chuẩn hóa trước khi huấn luyện. Dữ liệu được chia thành tập huấn luyện, validation và test ở mức bệnh nhân nếu có thể. Hiệu năng mô hình được đánh giá trên tập test độc lập bằng AUROC, độ nhạy, độ đặc hiệu, giá trị tiên đoán dương, giá trị tiên đoán âm và confusion matrix. Grad-CAM được sử dụng để trực quan hóa vùng ảnh đóng góp vào dự đoán của mô hình.
13.2. Mẫu Results
On the held-out test set, the model achieved an AUROC of ..., sensitivity of ..., specificity of ..., PPV of ..., and NPV of ... at a threshold of 0.5. Grad-CAM visualizations suggested that the model frequently focused on lung regions in correctly classified pneumonia cases. However, in several misclassified cases, attention maps highlighted non-pulmonary regions, suggesting potential shortcut learning or image quality issues.
Bản tiếng Việt:
Trên tập test độc lập, mô hình đạt AUROC = ..., độ nhạy = ..., độ đặc hiệu = ..., PPV = ... và NPV = ... tại ngưỡng phân loại 0,5. Trực quan hóa Grad-CAM gợi ý rằng mô hình thường tập trung vào vùng phổi ở các ca viêm phổi được phân loại đúng. Tuy nhiên, ở một số ca phân loại sai, heatmap tập trung vào vùng ngoài phổi, gợi ý khả năng mô hình học shortcut hoặc bị ảnh hưởng bởi chất lượng ảnh.
13.3. Mẫu Limitations
This model was developed as a proof-of-concept using a limited dataset and has not undergone external validation. Performance may vary across institutions, imaging devices, patient populations, and image acquisition protocols. The model should not be used for clinical decision-making without further validation and prospective evaluation.
Bản tiếng Việt:
Mô hình này được xây dựng như một minh chứng kỹ thuật trên dataset hạn chế và chưa được kiểm định ngoài. Hiệu năng có thể thay đổi giữa các bệnh viện, thiết bị chụp, quần thể bệnh nhân và quy trình thu nhận ảnh. Mô hình không nên được sử dụng cho quyết định lâm sàng nếu chưa có kiểm định ngoài và đánh giá tiến cứu.
PHẦN 14: CASE STUDY THẢO LUẬN
Case 1: Accuracy 95% nhưng mô hình vô dụng
Dataset có 95% ảnh bình thường, 5% ảnh viêm phổi. Mô hình đoán tất cả là bình thường và đạt accuracy 95%.
Câu hỏi
- Vì sao accuracy cao nhưng mô hình kém?
- Chỉ số nào cần xem thêm?
- Nếu triển khai, hậu quả là gì?
Gợi ý
Cần xem sensitivity, specificity, AUROC, PPV, NPV, F1-score. Mô hình bỏ sót toàn bộ viêm phổi nên không có giá trị lâm sàng.
Case 2: AUROC 0.99 — quá đẹp để tin?
Một mô hình phân loại X-quang đạt AUROC 0.99 trên test set.
Câu hỏi
- Có nên vui ngay không?
- Cần kiểm tra leakage nào?
- Có cần external validation không?
Gợi ý
Cần kiểm tra patient-level split, duplicate images, metadata leakage, text markers, preprocessing leakage, hospital leakage. AUROC quá cao trong dữ liệu y khoa cần nghi ngờ trước khi ăn mừng. Bánh sinh nhật để sau, kiểm tra leakage trước.
Case 3: Grad-CAM nhìn vào chữ trên ảnh
Mô hình dự đoán viêm phổi rất tốt, nhưng Grad-CAM tập trung vào chữ “portable” ở góc ảnh.
Câu hỏi
- Mô hình đang học gì?
- Vì sao nguy hiểm?
- Cách xử lý?
Gợi ý
Mô hình có thể học shortcut: ảnh portable thường đến từ bệnh nhân nặng/ICU nên dễ có viêm phổi. Cần crop/ẩn text marker, kiểm tra lại dataset, đánh giá external validation.
Case 4: Model dùng tốt ở bệnh viện trung ương nhưng kém ở tuyến tỉnh
Mô hình huấn luyện từ bệnh viện trung ương, khi dùng ở bệnh viện tỉnh thì sensitivity giảm mạnh.
Câu hỏi
- Vì sao?
- Cần làm gì trước khi triển khai?
- Có nên fine-tune bằng dữ liệu địa phương không?
Gợi ý
Có thể do khác biệt máy chụp, protocol, case-mix, chất lượng ảnh, nhãn. Cần external validation, calibration, subgroup analysis, và có thể fine-tune bằng dữ liệu địa phương đã được phê duyệt.
PHẦN 15: ĐẠO ĐỨC VÀ BẢO MẬT TRONG DEEP LEARNING HÌNH ẢNH
15.1. Những rủi ro chính
- Ảnh còn metadata định danh.
- Ảnh có tên/mã bệnh nhân in trên góc.
- Dataset không có phê duyệt đạo đức.
- Dùng ảnh bệnh viện cho cloud AI khi chưa được phép.
- Mô hình thiên lệch theo máy chụp hoặc bệnh viện.
- Grad-CAM bị diễn giải quá mức.
- Dùng mô hình demo như công cụ lâm sàng thật.
- Không khai báo AI/Deep Learning đúng trong báo cáo.
15.2. Checklist đạo đức
- Dataset có nguồn gốc rõ ràng.
- Có quyền sử dụng dữ liệu.
- Có phê duyệt đạo đức hoặc dataset public hợp lệ.
- Ảnh đã ẩn danh.
- Metadata DICOM đã xử lý.
- Không có chữ định danh trên ảnh.
- Chia dữ liệu ở mức bệnh nhân.
- Có đánh giá bias nếu có subgroup.
- Có external validation nếu muốn triển khai.
- Có AI disclosure trong báo cáo.
- Không dùng mô hình như chẩn đoán chính thức khi chưa được phê duyệt.
PHẦN 16: PROMPT THƯ VIỆN CHO BÀI 20
Prompt 1: Đánh giá bài toán Deep Learning có phù hợp không
Tôi muốn xây dựng mô hình Deep Learning cho hình ảnh y học.
Thông tin:
- Loại hình ảnh:
- Bệnh/case cần phát hiện:
- Outcome/label:
- Số ảnh:
- Số bệnh nhân:
- Ai gắn nhãn:
- Có dữ liệu từ bao nhiêu bệnh viện:
- Có phê duyệt đạo đức không:
- Dữ liệu đã ẩn danh chưa:
- Mục đích: nghiên cứu / hỗ trợ lâm sàng / demo học tập
Hãy đánh giá:
1. Bài toán có phù hợp Deep Learning không?
2. Nguy cơ thiếu dữ liệu là gì?
3. Nguy cơ data leakage là gì?
4. Cần chia train/validation/test thế nào?
5. Nên dùng transfer learning hay huấn luyện từ đầu?
6. Metrics nào cần báo cáo?
7. Cần kiểm tra đạo đức và bias gì?
Prompt 2: Viết code transfer learning
Hãy viết code Google Colab sử dụng TensorFlow/Keras cho bài toán phân loại ảnh y học nhị phân.
Dataset:
data/train/class0
data/train/class1
data/val/class0
data/val/class1
data/test/class0
data/test/class1
Yêu cầu:
1. Kiểm tra GPU
2. Load dataset bằng image_dataset_from_directory
3. Resize ảnh về 224x224
4. Data augmentation nhẹ cho train set
5. Dùng ResNet50 pretrained, include_top=False
6. Freeze base model
7. Thêm classification head cho binary classification
8. Train model
9. Vẽ learning curves
10. Đánh giá test set bằng AUROC, confusion matrix, sensitivity, specificity
11. Tạo Grad-CAM cho một ảnh mẫu
12. Comment code bằng tiếng Việt
Prompt 3: Kiểm tra data leakage
Tôi có pipeline Deep Learning cho ảnh y học như sau:
[Dán mô tả hoặc code]
Hãy kiểm tra nguy cơ data leakage:
1. Patient-level split có đảm bảo không?
2. Có ảnh trùng giữa train/test không?
3. File name hoặc metadata có chứa nhãn không?
4. Preprocessing có fit trên toàn dataset không?
5. Data augmentation có áp dụng sai cho test set không?
6. Có hospital/device leakage không?
7. Cần sửa pipeline thế nào?
Prompt 4: Diễn giải Grad-CAM
Tôi có Grad-CAM heatmap cho mô hình phân loại ảnh X-quang.
Thông tin:
- True label:
- Predicted label:
- Predicted probability:
- Vùng heatmap tập trung:
- Nhận xét của bác sĩ:
Hãy giúp tôi viết diễn giải thận trọng:
1. Heatmap gợi ý điều gì?
2. Không nên kết luận quá mức gì?
3. Nếu heatmap ngoài vùng tổn thương thì cần cảnh báo gì?
4. Cách viết trong manuscript thế nào?
Prompt 5: Viết phần Limitations cho mô hình ảnh y học
Tôi có nghiên cứu Deep Learning hình ảnh y học:
- Dataset size:
- Number of centers:
- Model:
- Internal validation:
- External validation:
- Label source:
- Metrics:
- Grad-CAM:
- Intended use:
Hãy viết phần Limitations bằng tiếng Anh học thuật và tiếng Việt, nhấn mạnh:
1. Dataset hạn chế
2. Thiếu external validation nếu có
3. Nguy cơ bias
4. Nguy cơ data leakage đã kiểm soát/chưa kiểm soát
5. Không dùng cho quyết định lâm sàng nếu chưa kiểm định tiến cứu
PHẦN 17: LỖI THƯỜNG GẶP VÀ CÁCH SỬA
| Lỗi | Ví dụ | Hậu quả | Cách sửa |
|---|---|---|---|
| Chia theo ảnh, không theo bệnh nhân | Một bệnh nhân ở cả train/test | AUROC ảo | Patient-level split |
| Dataset quá nhỏ | 100 ảnh, model rất sâu | Overfitting | Transfer learning, cross-validation, thêm dữ liệu |
| Chỉ báo cáo accuracy | Accuracy 95% với outcome hiếm | Đánh giá sai | Báo cáo AUROC, sensitivity, specificity |
| Không kiểm tra duplicate | Ảnh trùng ở train/test | Performance ảo | Hash image/check duplicates |
| Dùng ảnh chưa ẩn danh | Còn tên bệnh nhân trên ảnh | Vi phạm bảo mật | De-identification |
| Grad-CAM bị diễn giải quá mức | “Model hiểu tổn thương” | Overclaim | Viết “suggests attention” |
| Không external validation | Chỉ test nội bộ | Khó triển khai | Kiểm định bệnh viện khác |
| Dùng model demo cho lâm sàng | Chưa phê duyệt | Nguy cơ bệnh nhân | Chỉ dùng nghiên cứu |
| Không ghi version/code | Không tái lập | Kém minh bạch | Lưu notebook, seed, package versions |
| AI viết code nhưng không hiểu | Copy chạy máy móc | Sai pipeline | Review từng bước |
PHẦN 18: CHECKLIST SAU BÀI HỌC
Checklist kiến thức
- Hiểu CNN là gì.
- Giải thích được convolution/pooling.
- Hiểu transfer learning.
- Biết ResNet/VGG/EfficientNet là gì.
- Hiểu AUROC, sensitivity, specificity.
- Biết Grad-CAM dùng để làm gì.
- Hiểu data leakage trong hình ảnh.
- Hiểu bias và external validation.
Checklist kỹ thuật
- Mở được Google Colab.
- Bật GPU.
- Load dataset ảnh.
- Resize và preprocess ảnh.
- Dùng ResNet50 pretrained.
- Train classification head.
- Fine-tune một phần model.
- Tạo confusion matrix.
- Vẽ ROC curve.
- Tạo Grad-CAM.
Checklist đạo đức
- Dataset có quyền sử dụng.
- Ảnh đã ẩn danh.
- Metadata đã kiểm tra.
- Không đưa ảnh định danh lên AI/cloud không được phép.
- Có patient-level split.
- Có báo cáo hạn chế.
- Không kết luận mô hình thay thế bác sĩ.
- Có AI disclosure nếu dùng AI hỗ trợ code/phân tích.
PHẦN 19: BÀI TẬP VỀ NHÀ
Bài tập chính: Mini Deep Learning Imaging Report
Mỗi học viên hoặc nhóm nhỏ hoàn thành một notebook hoặc báo cáo ngắn.
Yêu cầu nộp
- Câu hỏi nghiên cứu
- Loại ảnh.
- Outcome.
- Intended use.
- Mô tả dataset
- Số ảnh.
- Số bệnh nhân nếu có.
- Số class.
- Nguồn dữ liệu.
- Cách gắn nhãn.
- Cách ẩn danh.
- Pipeline
- Train/validation/test split.
- Preprocessing.
- Data augmentation.
- Model architecture.
- Transfer learning strategy.
- Evaluation
- Confusion matrix.
- AUROC.
- Sensitivity.
- Specificity.
- PPV/NPV nếu phù hợp.
- Learning curves.
- Interpretability
- Ít nhất 3 Grad-CAM examples.
- Nhận xét vùng mô hình chú ý.
- 1 ví dụ model sai nếu có.
- Ethics and limitations
- Bảo mật dữ liệu.
- Bias.
- External validation.
- Không dùng lâm sàng nếu chưa phê duyệt.
- AI use reflection
- AI giúp gì trong code hoặc diễn giải?
- AI có gợi ý sai gì không?
- Bạn kiểm tra lại thế nào?
Mẫu bài nộp rút gọn
Project title:
Transfer learning for chest X-ray classification: normal vs pneumonia.
Dataset:
- Public chest X-ray dataset
- 1,000 images for training, 200 for validation, 200 for testing
- Classes: normal and pneumonia
Model:
- ResNet50 pretrained on ImageNet
- Feature extraction followed by fine-tuning of final layers
Evaluation:
- Test AUROC = ...
- Sensitivity = ...
- Specificity = ...
- Confusion matrix included
Grad-CAM:
- Correct pneumonia cases showed attention over lung opacities in most examples
- One false positive showed attention over non-lung region
Limitations:
- Dataset is public and may not represent Vietnamese hospitals
- No external validation
- Model is for education/research only, not clinical deployment
AI use:
ChatGPT was used to generate initial TensorFlow code and explain error messages. All code was reviewed and modified by the study team.
PHẦN 20: RUBRIC CHẤM ĐIỂM
| Tiêu chí | Điểm |
|---|---|
| Câu hỏi hình ảnh y học rõ ràng | 1 |
| Dataset được mô tả đầy đủ | 1 |
| Pipeline train/validation/test hợp lý | 1.5 |
| Áp dụng transfer learning đúng | 1.5 |
| Đánh giá mô hình đầy đủ: AUROC, sensitivity, specificity, confusion matrix | 1.5 |
| Có Grad-CAM và diễn giải thận trọng | 1 |
| Nhận diện data leakage/bias/limitations | 1 |
| Đạo đức và bảo mật dữ liệu được đề cập | 1 |
| Reflection về sử dụng AI có trách nhiệm | 0.5 |
| Tổng | 10 |
PHẦN 21: THÔNG ĐIỆP KẾT THÚC
Bài 20 mở cánh cửa vào Deep Learning cho hình ảnh y học. Đây là phần hấp dẫn, mạnh mẽ, nhưng cũng nhiều bẫy nhất.
Hãy nhớ 8 câu:
1. Deep Learning rất mạnh với hình ảnh, nhưng không tự động đúng.
2. CNN học pattern từ dữ liệu; nếu dữ liệu lệch, mô hình học lệch.
3. Transfer learning giúp bắt đầu nhanh, nhưng không thay thế validation nghiêm túc.
4. AUROC đẹp chưa đủ; cần sensitivity, specificity, confusion matrix và kiểm tra leakage.
5. Grad-CAM giúp nhìn mô hình chú ý ở đâu, nhưng không chứng minh mô hình “hiểu” bệnh.
6. Ảnh y học là dữ liệu nhạy cảm. Ẩn danh và bảo mật không phải phần phụ lục, mà là nền móng.
7. Mô hình demo trong lớp học không phải thiết bị y tế. Đừng để notebook Colab bước thẳng vào phòng khám.
8. AI hình ảnh tốt nhất là AI giúp bác sĩ nhìn kỹ hơn, nhanh hơn, an toàn hơn — không phải AI khiến con người ngừng suy nghĩ.
Soạn giả: Jack Doan
Phiên bản: 1.0
- Đăng nhập để gửi ý kiến
